Here is how I solved Week 5 of the Database Corruption Challenge. The following steps were tested and confirmed working on SQL Server 2008R2, SQL Server 2012, and SQL Server 2014.
To oversimplify, here are the steps:
- Restore the last known good database.
- Shut down the database, and copy off the last good database files.
- Replace some files and restart it. (Hack Attach)
- Next realizing that the boot page was corrupt page 1:9.
- Shut down the database.
- Copy the boot page from the last good database files and place it in the corrupt file.
- Restart the database.
- Realize there is other corruption.
- Fix the other corruption.
Here are the exact steps I took.
-- solution to corruption challenge #5 by Steve Stedman select @@Version; USE [master] GO -- lets start by looking at what files the backup contains. RESTORE FILELISTONLY FROM DISK = N'C:\DBBackups\CorruptionChallenge5_FullBackup1.bak' ;
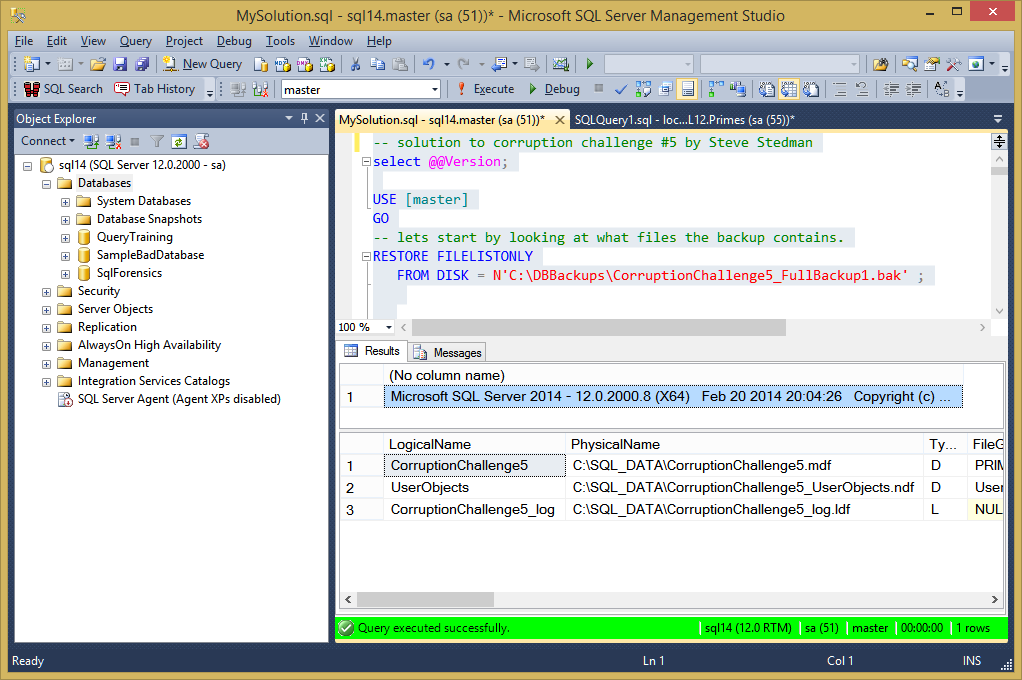
RESTORE DATABASE [CorruptionChallenge5] FROM DISK = N'C:\DBBackups\CorruptionChallenge5_FullBackup1.bak' WITH FILE = 1, MOVE N'CorruptionChallenge5' TO N'C:\SQL_DATA\CorruptionChallenge5.mdf', MOVE N'UserObjects' TO N'C:\SQL_DATA\CorruptionChallenge5_UserObjects.ndf', MOVE N'CorruptionChallenge5_log' TO N'C:\SQL_DATA\CorruptionChallenge5_log.ldf', RECOVERY, REPLACE;
Next I used the known good database, and confirmed that there is no corruption. There were no errors returned from CheckDB
USE CorruptionChallenge5; GO DBCC CheckDB(CorruptionChallenge5) WITH NO_INFOMSGS;
Next, I take a look at the Orders table, which I know is where the corruption is from my first run through on this process.
SELECT * FROM Orders; -- 16622 rows

Next I query what is at id # -2147471111. I now that this is the missing for because this is the second time that I ran through the script. The first time through I had no idea what was missing, and I didn’t do this. This is one reason that you should always consider how you can do-over your work if you run into trouble.
SELECT * FROM Orders WHERE id = -2147471111; -- id orderDate customerId shippingType orderDetails -- -2147471111 2013-04-10 13:44:47.413 331 Next Day C9008681-C983-4621-8770-A52215DC3B64 this is the order details...

Next I select from Customers just to see how many rows there are.
SELECT * FROM Customers; -- 400 rows
Now we move on to figuring out the corruption. We set the [CorruptionChallenge5] database to offline, and replace the data files, to be used for the hack attach.
USE master; GO -- Set to OFFLINE ALTER DATABASE [CorruptionChallenge5] SET OFFLINE WITH ROLLBACK IMMEDIATE; GO -- stop here and save off the existing database files -- and replace with those from the challenge.
First we copy off all three of the database files to save in another directory for use later.
Now we copy in the three files provided in the challenge, the MDF, NDF and LDF files.
-- Bring the database back online ALTER DATABASE [CorruptionChallenge5] SET ONLINE; GO
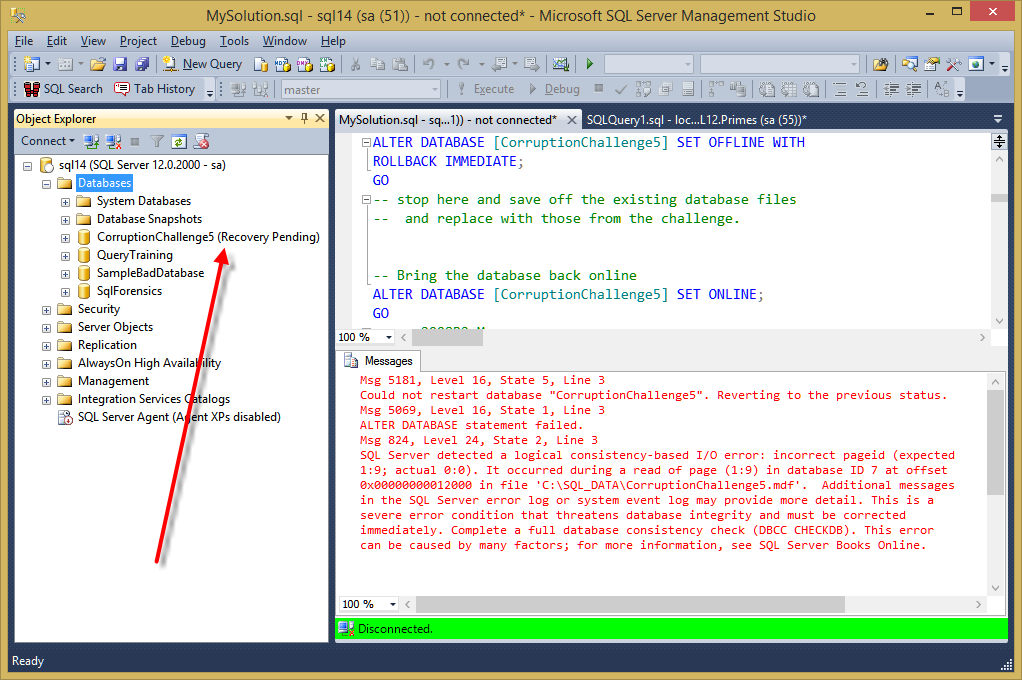
When the database attempts to come online notice that it is stuck in the Recovery Pending state. With the following error:
Msg 5181, Level 16, State 5, Line 3
Could not restart database “CorruptionChallenge5”. Reverting to the previous status.
Msg 5069, Level 16, State 1, Line 3
ALTER DATABASE statement failed.
Msg 824, Level 24, State 2, Line 3
SQL Server detected a logical consistency-based I/O error: incorrect pageid (expected
1:9; actual 0:0). It occurred during a read of page (1:9) in database ID 7 at offset
0x00000000012000 in file ‘C:\SQL_DATA\CorruptionChallenge5.mdf’. Additional messages
in the SQL Server error log or system event log may provide more detail. This is a
severe error condition that threatens database integrity and must be corrected
immediately. Complete a full database consistency check (DBCC CHECKDB). This error
can be caused by many factors; for more information, see SQL Server Books Online.
Next we take a look at what is in the boot page.
And then…
DBCC TRACEON(3604) WITH NO_INFOMSGS; DBCC Page(CorruptionChallenge5, 1, 09, 2) WITH NO_INFOMSGS;
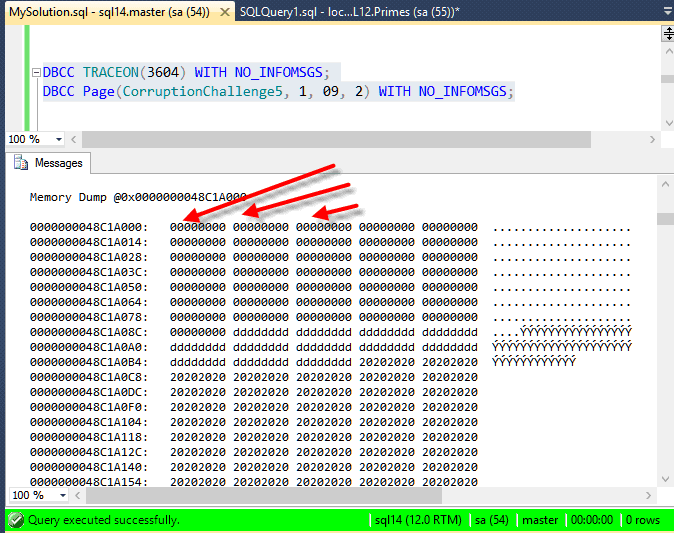
From here we can see that the boot page (1:9) is corrupt. From the very first byte we can see that this doesn’t look like a SQL Page.
We know that the boot page is good in .mdf file from the last known good backup, so we can try to just steal that page from the old file with a hex editor. First we need to set the database to OFFLINE.
-- Set to OFFLINE ALTER DATABASE [CorruptionChallenge5] SET OFFLINE WITH ROLLBACK IMMEDIATE;
I originally saw this in a presentation from Paul Randal at PASS Summit 14.
We go to address 0x12000 which is the start of page 9. From here we copy a full page of 0x2000 bytes.
When we paste, we need use “Paste Write” otherwise it will insert the page instead of overwriting the corrupt page.
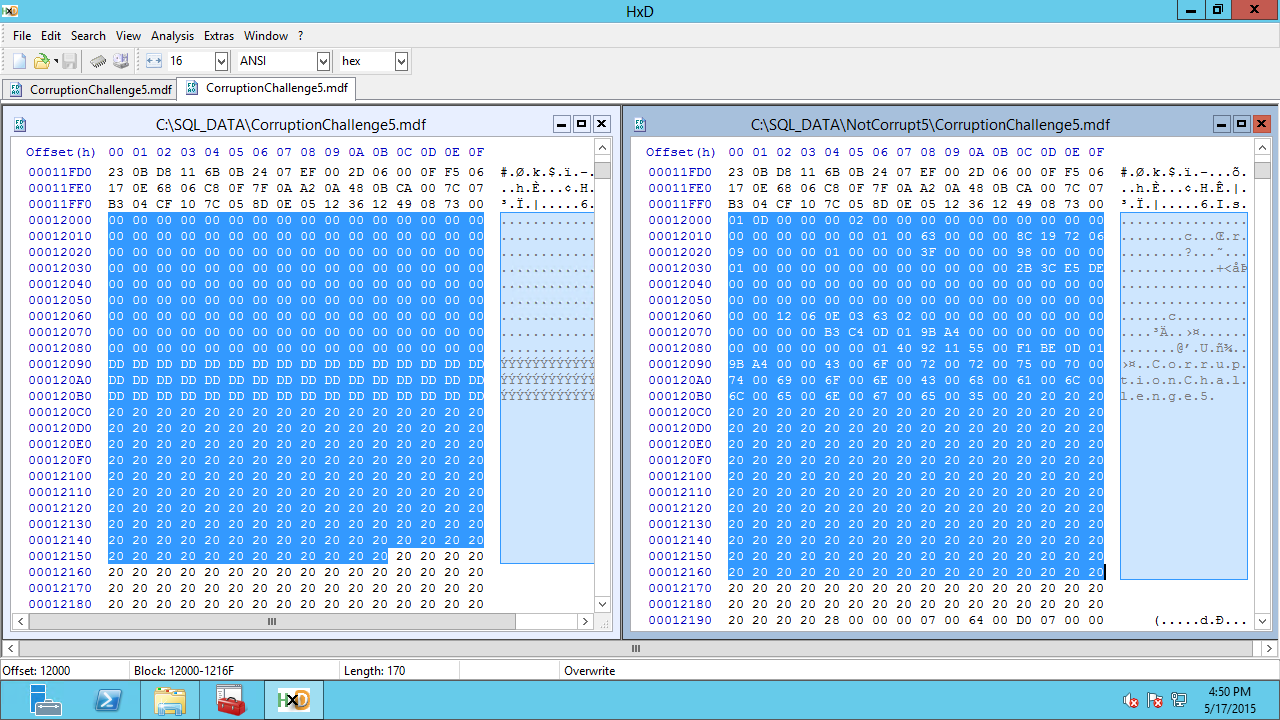
After doing the Hex Edit copy, we attempt to bring the database online.
ALTER DATABASE [CorruptionChallenge5] SET ONLINE; GO
Which shows us that we have more corruption somewhere.

So we now go into emergency mode and run CheckDB
ALTER DATABASE [CorruptionChallenge5] SET EMERGENCY; DBCC CheckDB(CorruptionChallenge5) WITH NO_INFOMSGS;

From here we can see that in page (3:175) which is in the [Orders] table.
use CorruptionChallenge5; GO SELECT * FROM sys.objects WHERE object_id = 2105058535;
So now we attempt to see what we can get out of the [Orders] table.
USE [CorruptionChallenge5]; GO SELECT * FROM Orders ORDER BY id ASC; --GOOD UP TO -2147471112 -- 12536 rows
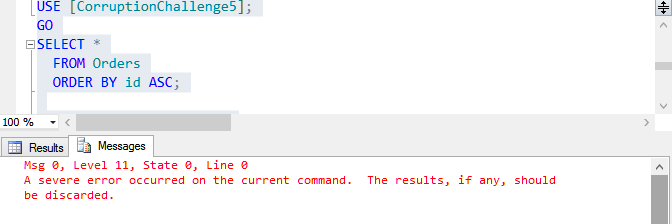
We can see that the data is good up to ID # -2147471112 or 12536 rows. But the messages window shows us errors.
Next we run a SELECT * ordering by id DESC which gives us all the data that can be located from the end of the table backwards.
SELECT * FROM Orders ORDER BY id DESC; --GOOD after -2147471110 -- 266 rows
We now know that the data is good after -2147471110 and before -2147471112 which leaves us knowing the bad row must be -2147471111. I saved this off earlier because this is my second time running through the attempted solution.
Next we insert into an temp table called #OrdersSaved.
SELECT * INTO #OrdersSave FROM (SELECT * FROM Orders WHERE id <= -2147471112 UNION SELECT * FROM Orders WHERE id >= -2147471110 ) as t ;
(12802 row(s) affected)
Now we run the typical check to confirm what indexes we may have available.
-- now what indexes do we have available?
SELECT ind.name as IndexName,
col.name as ColumnName,
ic.is_included_column
FROM sys.indexes ind
INNER JOIN sys.index_columns ic ON ind.object_id = ic.object_id and ind.index_id = ic.index_id
INNER JOIN sys.columns col ON ic.object_id = col.object_id and ic.column_id = col.column_id
WHERE ind.object_id = OBJECT_ID('Orders')
AND ind.is_unique = 0
AND ind.is_unique_constraint = 0
ORDER BY ind.name, ind.index_id, ic.index_column_id;
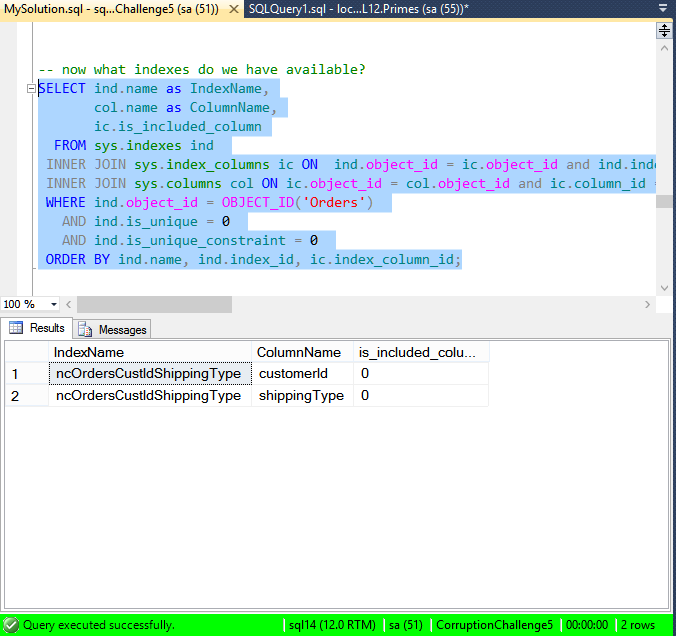
We don’t have enough columns to rebuild the missing item, but we can confirm that it does exist in the index, and that it is broken in the clustered index.
SELECT id, customerId FROM Orders; -- 12803 rows
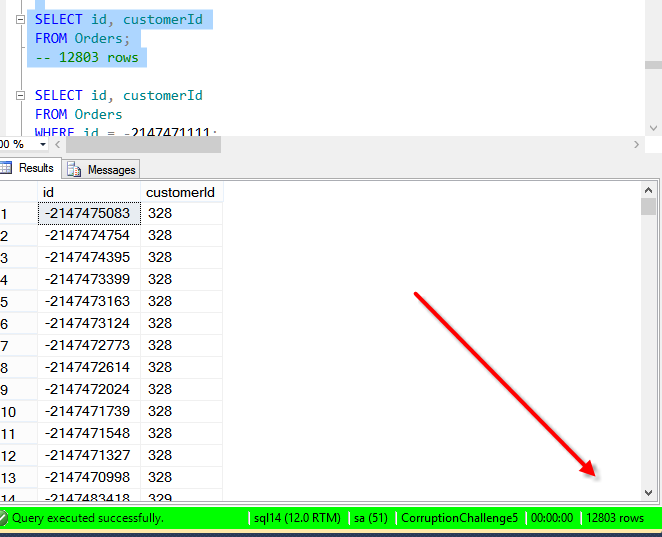
We compare the one row that we think is missing between the nonclustered index and the clustered index.
SELECT id, customerId FROM Orders WHERE id = -2147471111; SELECT * FROM Orders WHERE id = -2147471111;
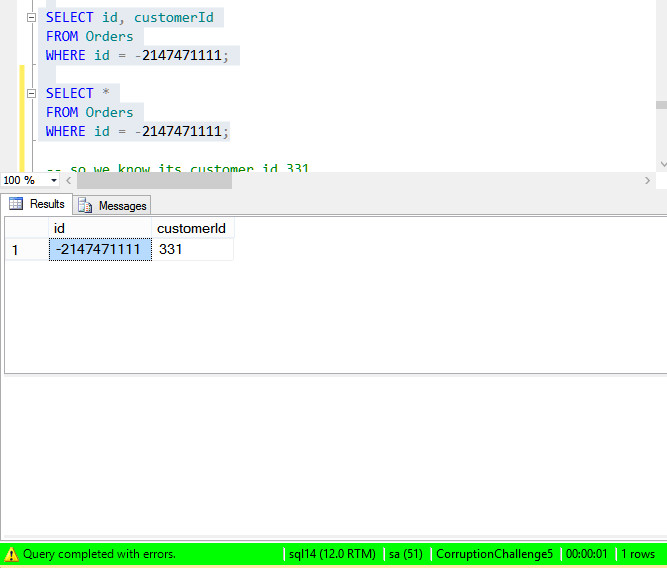
From here we know for sure that -2147471111 is the corrupt row. The first time through the process I had to go back to the beginning and get this out of the original backup database. But since this is the second time through, I have the corrupt row.
So now we first attempt to fix it, then we fix the corrupt table.
USE [CorruptionChallenge5]; GO ALTER DATABASE [CorruptionChallenge5] SET SINGLE_USER WITH ROLLBACK IMMEDIATE; -- first try to rebuild DBCC CheckTable(Orders, REPAIR_REBUILD); DBCC CheckDB([CorruptionChallenge5], REPAIR_REBUILD); GO SELECT * FROM Orders; -- no good, nothing changed GO
As usual we are not lucky enough for REPAIR_REBUILD to work. Now on to try repairing with data loss. Which translates to CheckDB just throwing out the pages that it sees as corrupt.
[/sql]
— DANGER DANGER DANGER
— the following causes parts of the table to be lost.
USE [CorruptionChallenge5];
DBCC CheckDB([CorruptionChallenge5], REPAIR_ALLOW_DATA_LOSS);
DBCC CheckDB([CorruptionChallenge5]) WITH NO_INFOMSGS;
[/sql]
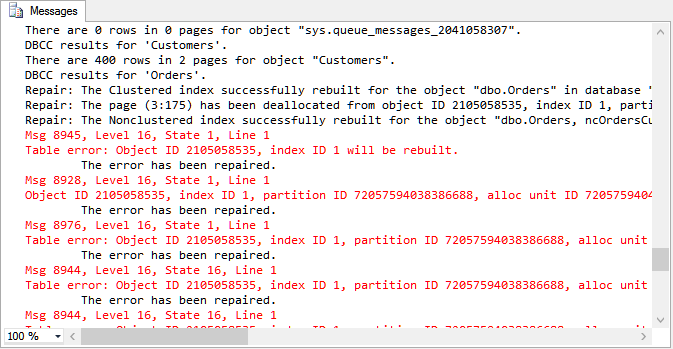
We can see that the corruption is fixed. Now to see what is missing.
SELECT * FROM #OrdersSave WHERE id NOT IN(SELECT id FROM [Orders]); -- 78 rows in #OrdersSave that are not in [Orders]
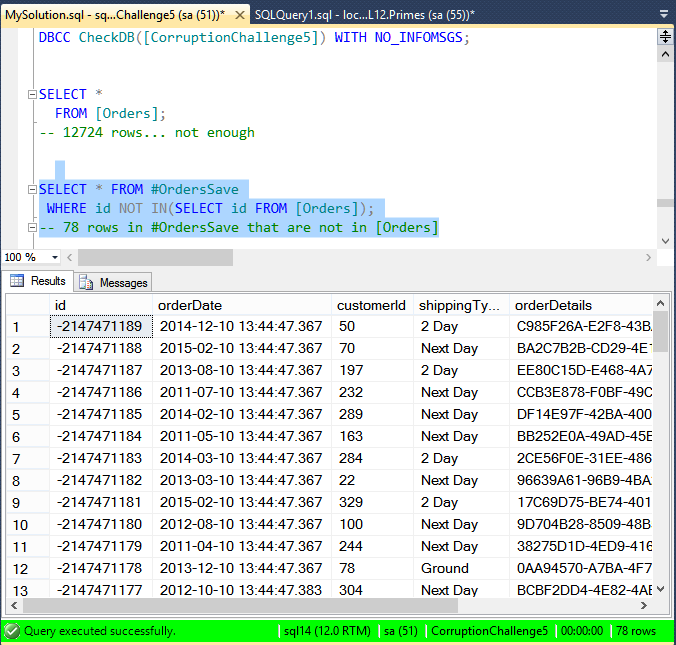
So let’s put back the missing rows.
-- so now lets move the missing rows from #OrdersSave SET IDENTITY_INSERT [Orders] ON; INSERT INTO [Orders] (id, orderDate, customerId, shippingType, orderDetails) SELECT * FROM #OrdersSave WHERE id NOT IN(SELECT id FROM [Orders]); INSERT INTO Orders (id, orderDate, customerId, shippingType, orderDetails) VALUES (-2147471111, '2013-04-10 13:44:47.413', 331, 'Next Day', 'C9008681-C983-4621-8770-A52215DC3B64 this is the order details...'); SET IDENTITY_INSERT [Orders] OFF; SELECT * FROM [Orders]; -- how many rows now? -- 12803
We can see that we are back to 12803 rows which is what we determined we were looking for earlier.
Let’s finish up.
ALTER DATABASE [CorruptionChallenge5] SET MULTI_USER; USE CorruptionChallenge5; GO SELECT * FROM Orders; DBCC CheckDB([CorruptionChallenge5]);
And the corruption is gone. Time to back up the database since we are back to a known good spot.
Related Links
- Current Scores
- Newsletter Sign up
- Database Corruption Challenge T-Shirt
- Week 1, Week 2, Week 3, Week 4, Week 5
- Database Corruption Worksheet

More from Stedman Solutions:

Steve and the team at Stedman Solutions are here for all your SQL Server needs.
Contact us today for your free 30 minute consultation..
We are ready to help!
After modifying the boot page, I had to add another step.
On attempting to bring the database back ONLINE, I was getting the error
Msg 5120, Level 16, State 101, Line 19
Unable to open the physical file “c:\SQL_DATA\CorruptionChallenge5.mdf”. Operating system error 5: “5(Access is denied.)”.
and this was because the SQL Server service account on my machine had no permissions on the corrupt (now hacked) mdf file. My install is using the Virtual Account/ Managed Service Account setup, so I needed to edit the security properties of the mdf and add the ‘user’ NT SERVICE/MSSQL$SQL2014 (where SQL2014 is the instance name), and assign Full control over the mdf.
(note you cannot find this name in any pick-list in the dialog, you have to know your service name and type it in – to find the account I looked at the permissions on either the ndf or ldf)
After doing this I could then bring the database back online into the SUSPECT state.
Hope this helps anyone else having similar problems.
Good point. Yes, depending on how your SQL Server Service is configured you may need to modify the permissions on the files to attach them as you mentioned.
Thanks for pointing that out.
-Steve Stedman