It is my pleasure to announce this weeks winners in the Database Corruption Challenge – Week 2.
There were many great solutions submitted, and I hope that everyone learned something from this weeks challenge.
My favorite part of the whole challenge was this post on Twitter…
The whole goal of the Database Corruption Challenge is to help everyone be better prepared for when they do encounter corruption.
On to the winners. Here is this weeks list of winners with the first one to submit a correct solution being Rob Farley
#1 Rob Farley
- #2 – Nicolette Carpenter Boddie
- #3 – Parikshit Savjani
- #4 – Ivan Rodriguez Camejo
- Subhro Saha
- Neil Abrahams
- Rui Bastos
- Lucas Kartawidjaja
- Piche Sebastien
- Bogdan Sahlean
- Raul Gonzalez
- Pasquale Ceglie
- David Patterson
- Patrick Flynn
- Arthur Baan
- André Kamman
- Prageet Surheley
The timing between #1, #2 and # 3 was very close. Solution #3 came in about 7 minutes after #1, and #3 was about 8 minutes later.
For those who haven’t signed up yet, I have created a newsletter where you can sign up to get notification ahead of time when the next corruption challenge will be started.
The winning solution
Rob Farley provided the winning solution, shown here. Note: SQL formatting has been changed to fit the blog post.
He first restored the databases to CorruptionChallenge2, and CorruptionChallenge2_OLD.
What I like about this solution was that all of the records were located and stored in another table Rev2a prior to anything being deleted, truncated, or cleaned up. The three queries shown here with the UNION ALL connecting them find the missing data. The first one finds all the data before the corrupt page. The second query finds everything after the corrupt page. The last part pulls the rows in from the backup database using the ncDeptIdYear index from the corrupt table to find the rows that need to be inserted.
SELECT *
INTO dbo.Rev2a
FROM (SELECT TOP 595 *
FROM CorruptionChallenge2.dbo.Revenue
ORDER BY id ASC) t1
UNION ALL
SELECT *
FROM (SELECT TOP (9450) *
FROM CorruptionChallenge2.dbo.Revenue
ORDER BY id DESC) t2
UNION ALL
SELECT *
FROM CorruptionChallenge2_OLD.dbo.Revenue
WHERE id IN
(
SELECT id
FROM CorruptionChallenge2.dbo.Revenue WITH (INDEX(ncDeptIdYear))
WHERE id NOT IN
(SELECT id FROM (SELECT TOP 595 *
FROM CorruptionChallenge2.dbo.Revenue
ORDER BY id ASC) t1
UNION ALL
SELECT id
FROM (SELECT TOP (9450) *
FROM CorruptionChallenge2.dbo.Revenue
ORDER BY id DESC) t2
)
);

Once that query was run, you can see there were 10057 rows inserted into the table Rev2a which was then used to help fix things up. Next lets take a look at what is in Rev2a.
SELECT * FROM dbo.Rev2a;
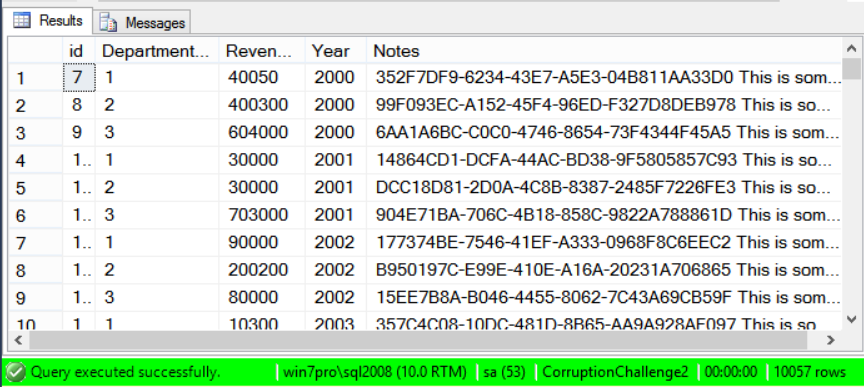
Now here is how Rob took care of the corruption with TRUNCATE table on the Revenue table, then he refilled it with the right data.
TRUNCATE TABLE dbo.Revenue; GO SET IDENTITY_INSERT dbo.Revenue ON; GO INSERT dbo.Revenue (id, DepartmentID, Revenue, Year, Notes) SELECT * FROM dbo.Rev2a; GO SET IDENTITY_INSERT dbo.Revenue OFF; GO
Next he cleaned up his Rev2a table that was used to hold the data.
DROP TABLE dbo.Rev2a;
Then he ran the check procedure to confirm that his solution was correct, which it was.
EXEC dbo.checkCorruptionChallenge2Result;
The stored procedure to check the solution was something new that I added, and there were a number of comments from people about it. I did give people a way of telling if they got things right, however it didn’t simulate a real world experience, as in the real world, there will be no magic stored procedure to run that tells you if you fixed the corruption.
That is how this weeks database corruption challenge was won.
Again, I would like to congratulate everyone who participated and either learned something new or had a chance to practice their skills.
Stay tuned for the next corruption challenge next week, and this week I will post a few of the other winning solutions.
-Steve Stedman
Related Links:
- Database Corruption Worksheet
- Corruption Challenge Week 1
- Corruption Challenge Week 2
- Stedman Solutions (my consulting business)
More from Stedman Solutions:

Steve and the team at Stedman Solutions are here for all your SQL Server needs.
Contact us today for your free 30 minute consultation..
We are ready to help!
I should point out that I had started to explore other options for making sure there weren’t other changes between the earliest backup and the corruption, but decided to run the testing stored procedure to see if it gave any clues. When it said that I had solved, I didn’t keep looking, and just emailed Steve to let him know what I’d done.
Rob – I may be missing something obvious here, but what method did you use to determine where to stop and start selecting rows before and after page 244? i.e. the first 595, and last 9450 rows. Did you just inspect pages using DBCC PAGE?
Oops – hadn’t noticed these questions to me.
It was trial & error. I ran TOP with half the data. If I got an error, I shrank the number, and raised it otherwise. Pretty quickly I found the number that I could reliably access, from each end.
Rob,
could you please explain to us how did you determine where to stop. On page 243 there are records from 589 to 601 so did you start selecting where ID= 601, Id = 600, …until 595 where the query returns no corruption and after that you select count(ID)from Revenue returns 10057. You looked at the last page on the revenue table using dbcc ind(‘DBNAME’,’revenue’,1)so the last page is 917, and dbcc page (DB_ID,1,917,3) returns that the last record is id 10064. You did the math again 10064-595-19 = 9450
19 is the number of records corrupted in page 244 and 243
Nothing so fancy – I just varied my TOP values to find it. Started around half way and narrowed it down.
Both the stored procedure and this answer imply that a full restore should have 10057 rows. I do not believe this is correct. There should be 10058 rows in the restored table. Please help me understand where I am wrong.
There 10054 rows on the backup from 2 days ago (Revenue_B1)
6 of these are deleted from the current database (ID 1-6)
There are 10 new rows (id = 10055-10064)
10054 (2 days ago) + 10 (new) – 6 (Delete) = 10058
There are 13 corrupted rows (id = 602-614), not that it matters for the math.
My restore has 10058 rows, with ID 7-10064. I have done several compares and not finding where I might have added an extra row.
Hi James,
I had the same issue initially, the extra row is id 610.
610 is on the corrupt page, but was deleted between the backup and time of the corruption.
The way Rob gets round this is by using the non-corrupt index ncDeptIdYear (from the corrupt database) to list the IDs where he doesn’t have clean rows. So he avoids pulling back the deleted row in the old database.
I didn’t understand the purpose of using table hint below:
WITH (INDEX(ncDeptIdYear))
With or without using this hint, same data will be returned.
Meysam – In a perfect world, the same data would be returned with our without that index hint, however when dealing with a table that is corrupt the index may have different rows that the table itself has in it.
Technically I may not have worded that first part correctly, as the table and index should have the same rows, but due to the corruption, the row in the table (clustered index) may not be accessible. We are using the non-clustered index to find those that are not accessible.
With corruption, assumptions like the index and the table returning the same rows is not always true. That is what makes the repairing of corruption so interesting.
Hope this helps explain things.
-Steve Stedman