On Saturday morning, I announced the Database Corruption Challenge, and I had to abbreviate it as the DBCC, why not, acronym overloading isn’t always a bad thing.
There were 91 participants, 22 of which ended up with correct answers with no corruption and no data loss.
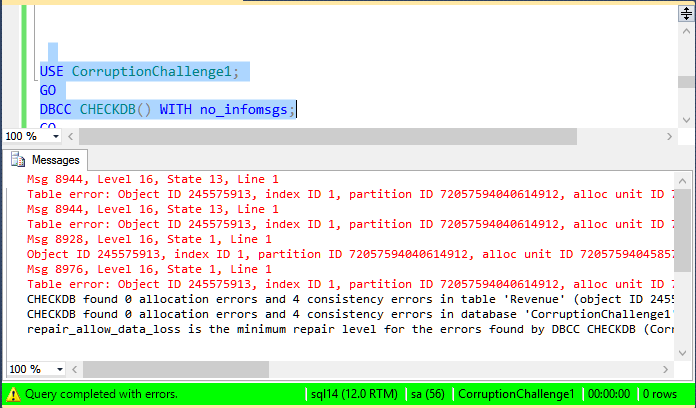
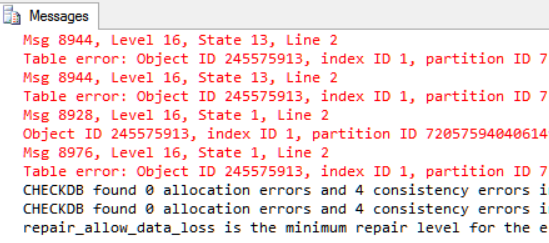
I created a database, with 3 bytes of corruption in one of the leaf node pages of a clustered index, however all I stated was that the database was corrupt, and it could be fixed with no data loss.
The number of different ways that people solved the problem was amazing. There were many attempts that did remove the corruption, and did recover all the rows, however many judged success as having the same number of rows as before, as a success. There were so many successful solutions that I think I will post one a day for the rest of the week, with the details explained. One solution even involved editing the database file on disk with a hex editor. I don’t have time to post all the good solutions right now.
The original corrupt database had been created on SQL Server 2014, but many people contacted me stating that they didn’t have SQL Server 2014 on their home computer, so I ended up creating a SQL Server 2008 version of the problem, but some were so driven to solve the challenge that they ended up installing SQL Server 2014 just to work the problem.

Nice work John. Thanks for playing along, I hope you enjoyed the experience. The next tweet from Mike Fal followed the post from John Morehouse.

I hope that John took this comment from Mike Fal as a great compliments, however it was soon corrected by AJ Mendo that it is more geek than nerd.
Either way, geeks or nerds, it was a good learning experience for those involved, and for me having to evaluate each solution to determine if it was indeed a valid solution with no data loss. Personally I ended up restoring the corrupt database and testing different solutions over 50 times this weekend.
Read More »A Weekend Full of Database Corruption