Corruption Challenge 9 Update
Just about 24 hours after releasing Database Corruption Challenge #9, so far there have been 15 winning solutions. The first to submit a winning solution… Read More »Corruption Challenge 9 Update
Just about 24 hours after releasing Database Corruption Challenge #9, so far there have been 15 winning solutions. The first to submit a winning solution… Read More »Corruption Challenge 9 Update
With many participants and 16 who correctly solved Corruption Challenge week 8, the challenge has come to an end. The overall winner was Rob Farley, and there were several new participants this week. The scores page has been updated.
Some participants called this the toughest challenge yet which makes my job even harder to come up with something more challenging for next time. There were a couple interesting twists in this one. One was the way the corruption caused issues with DBCC Page. On SQL Server 2014 DBCC Page on the corrupt page with the output parameter of 3 didn’t work, and the only output option that worked was option 2. However on SQL Server 2008R2 and 2012, none of the DBCC Page output options worked on the corrupt page, which forced some to open the database file with a hex editor to pull the data in from the corrupt page.
The one thing that I didn’t judge anyone badly with was the capitalization of the person in the corrupt record. I accepted EMMA, E WILLIAMS, and Emma, E Williams, and Emma, E WILLIAMS all as correct answers, as to figure out any of those it took the same amount of work.
The solution by Rob Farley:
Several participants have stated that week 8 is the most difficult week yet. However it is possible to recover all of the corrupt data. For… Read More »Extra clue added for Database Corruption Challenge Week 8
Database Corruption Challenge #8 will be starting at 6:00pm today (Friday June 19th). Check back soon for the details. Are you feeling corrupt? -Steve… Read More »Database Corruption Challenge #8 – Coming Soon
Lately several people have asked me for the solutions to the corruption challenge, so I thought it would be a good time to recap the last 7 weeks.
How do you check if a database exists, drop it and recreate it for testing purposes? After running the Database Corruption Challenge for several weeks… Read More »How Do You Check if a Database Exists…
 Welcome to the seventh week of 10 in the Database Corruption Challenge (DBCC), this is an about weekly competition. Here is how it works; I have created a corrupt database, hopefully more corrupt or more interesting than the previous week. I then solved the corruption myself in order to prove that it is possible to fix, without data loss.
Welcome to the seventh week of 10 in the Database Corruption Challenge (DBCC), this is an about weekly competition. Here is how it works; I have created a corrupt database, hopefully more corrupt or more interesting than the previous week. I then solved the corruption myself in order to prove that it is possible to fix, without data loss.
For any first time participants in Week 7, you can be part of a special prize group. I realize for those who are joining the competition now it isn’t possible to score enough points to compete with the current leaders. I will post a separate 3 week leader board for the last 3 weeks of the competition. To be considered in this section, you need to meet the following criteria:
The challenge will be to download the corrupt or somehow damaged database and attempt to recover it. If you can recover it, please send me the steps you used to recover the database, along with some proof that the database has been recovered. The goal each week will be the following:
Those who are subscribed to my newsletter will receive the exact time of the next corruption challenge. For those who have not subscribed, just keep checking… Read More »Database Corruption Challenge #7 Coming Soon
If you are looking for more info on the corrupt database with Week 6 of the Database Corruption Challenge, you can take a look at the original post.
Week 6 was won by Raul Gonzalez who submitted his winning solution just 45 minutes after the challenge began. Raul has solved 4 of the 6 challenges so far, and has scored 2 extra points for linking to the challenge, and commenting on the CheckDB post.
The solution this week was in the non-clustered index, and there was some corruption in the clustered index. If you were to just drop and recreate the non-clustered index, the corruption in the clustered index was not able to be found. Comparing the values in the non-clustered index to the clustered index show where the corruption exists.
Lets take a look at his solution. The only thing I changes was the directory paths on the restore to match my configuration.
USE master
GO
IF DB_ID('CorruptionChallenge6') IS NOT NULL BEGIN
ALTER DATABASE CorruptionChallenge6 SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE CorruptionChallenge6
END
GO
IF OBJECT_ID('tempdb..#fromIndex') IS NOT NULL DROP TABLE #fromIndex
IF OBJECT_ID('tempdb..#fromTable') IS NOT NULL DROP TABLE #fromTable
IF OBJECT_ID('tempdb..#goodData') IS NOT NULL DROP TABLE #goodData
RESTORE FILELISTONLY
FROM DISK = 'C:\DBBackups\CorruptionChallenge6.bak'
GO
RESTORE DATABASE CorruptionChallenge6
FROM DISK = 'C:\DBBackups\CorruptionChallenge6.bak'
WITH NORECOVERY, REPLACE
, MOVE 'CorruptionChallenge6' TO 'C:\SQL_DATA\CorruptionChallenge6.mdf'
, MOVE 'CorruptionChallenge6_log' TO 'C:\SQL_DATA\CorruptionChallenge6_log.ldf'
GO
RESTORE DATABASE CorruptionChallenge6 WITH RECOVERY
GO

Read More »Week 6 – The Winning Solution – Database Corruption Challenge
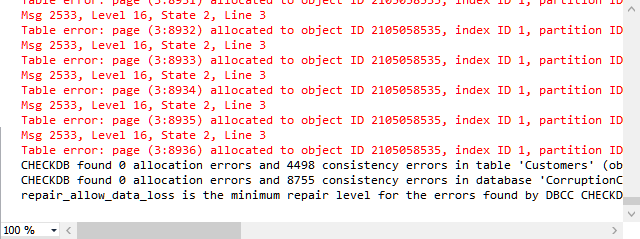
There are many times that CheckDB ends up being extremely slow, sometimes taking more than a day to run. This can make life difficult if you are trying to find out what is corrupt.
DBCC CheckDB(MyBigDatabase) WITH NO_INFOMSGS;
There are several of the tricks that I use to speed up DBCC CheckDB, depending on the specific environment. What I am looking for is what others do when they need to run DBCC CheckDB on a big database that appears to take forever to complete?