Don’t Reboot SQL Server So Often
How often should I reboot SQL Server? It is a common belief with computers that rebooting cleans things up in memory and that they run… Read More »Don’t Reboot SQL Server So Often
How often should I reboot SQL Server? It is a common belief with computers that rebooting cleans things up in memory and that they run… Read More »Don’t Reboot SQL Server So Often
Database Corruption Overview: Database corruption is one of those things that you can only plan for by practicing your response pla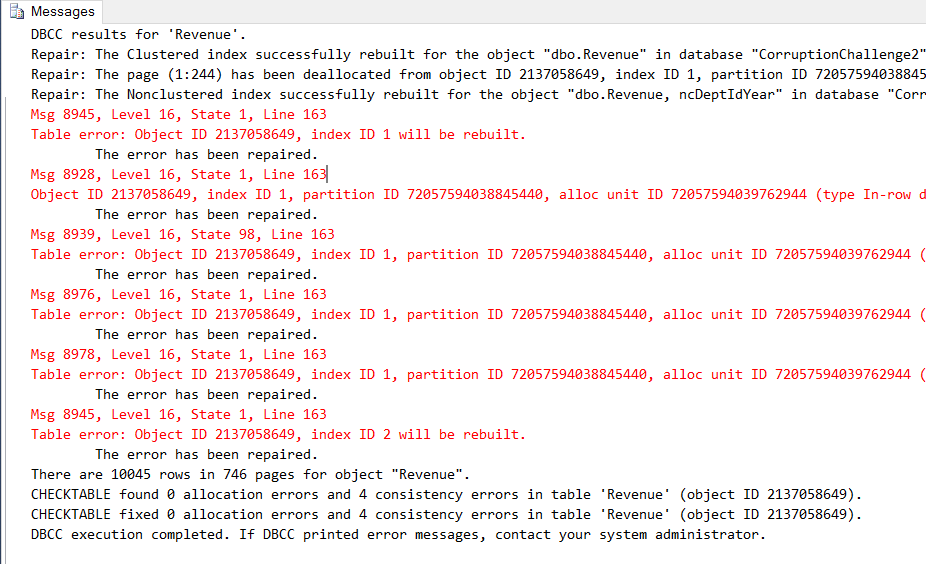 n. Out of all of the things that can happen to your SQL Server this is the one that you are most likely going to want to ask for help when you encounter it.
n. Out of all of the things that can happen to your SQL Server this is the one that you are most likely going to want to ask for help when you encounter it.
Database corruption refers to corrupt pages in the database that are incorrectly formatted. This could be as simple as a single bit, or as huge as the entire file. Sometimes this type of corruption prevents the database from starting, other times it may prevents queries from running. Sometimes it may go undetected for some time, and may present as missing or incorrect data.
This weeks latest podcast is an interview with Melissa Coates, on the topic of Cortana Intelligence Suite. From this weeks podcast: The Cortana Intelligence Suite… Read More »Cortana Intelligence Suite – Podcast Episode #62.
One way to improve performance on SQL Server is with IFI or Instant File Initialization.
Normally files are zeroed out on a database growth during an AUTOGROW, RESTORE, CREATE DATABASE or ALTER DATABASE. This is done by SQL Server when the file grows, it runs through that file and writes zeroes to the entire new allocation in the file. The zeroing process can take a great deal of time, the Instant file initialization process skips this zeroing, and just allocates the file. This works since SQL Server will just write each 8k page to disk as they are used, thus overwriting the uninitialized file.
Running some tests on a local virtual machine running SQL Server 2012 (similar results tested on SQL Server 2014 and SQL Server 2016), here is what I found.
For IFI to work, the user account that SQL Server is running as needs the “Perform volume maintenance tasks” policy to be enabled.Read More »Instant File Initialization (IFI)
Today on the tuning minute on the SQL Data Partners Podcast, we discussed duplicate indexes, which lead me to think more about and and write this post.
You know there are many different ways of doing things in SQL Server, and often times you can argue that one way or the other is better, and given the right situation anything might be a good idea. However duplicate indexes are a different story.
When I talk about duplicate indexes, what I mean is 2 or more indexes on the same table that are exactly the same columns. Something like this:
CREATE NONCLUSTERED INDEX [IX_LastName] ON [dbo].[Customer] ( [Lastname] ASC ); CREATE NONCLUSTERED INDEX [dta123123123_LastName] ON [dbo].[Customer] ( [Lastname] ASC );Two indexes on exactly the same column. There is nothing to be gained here.
The following Database Corruption Video is from the High Availability Disaster Recovery Virtual Chapter Presentation on September 13, 2016. Today I had the opportunity to… Read More »Database Corruption Video – HA DR Chapter