Tables, and indexes are organized in SQL Server into 8K chunks called pages. If you have rows that are 100 bytes each, you can fit about 80 of those rows into a given page. If you update one of those rows to have more data that contains a variable length field like VARCHAR, NVARCHAR, and others, that will cause the page to overflow forcing a page split. The page split takes about half of the data and moves it into a new page, leaving about half in the original page. Another action that causes a page split is to insert a row that based on the indexing would go into a page that is nearly full, if the inserted row doesn’t fit a page split occurs.
If there is room, and your update or insert doesn’t require a split, this is pretty quick to do since SQL Server is just updating one page and then writing it to disk, and to the transaction log. But if the updated or inserted row doesn’t fit, SQL Server needs to allocate a new page, move about half the rows, and then write both pages to disk and to the transaction log. Additionally the pages in all the indexes that point to the data pages need to be updated. Let’s say your table had 1 clustered index, 4 nonclustered indexes, at a minimum 7 pages would be updated, 1 for the clustered index structure, 4 for the nonclustered indexes, and 2 in the data pages in the clustered index. In this specific example the page split would cause a minimum of 7 times the I/O as an insert or update that didn’t require a page split.
Fill Factor
When an index is created with a fill factor percentage, this leaves a percentage of the index pages free after the index is created, rebuilt or reorganized. This free space is used to hold additional pages as page splits occur, reducing the change of a page split in the data page causing a page split in the index structure as well, but even with your Fill Factor set to 10% to 20%, index pages eventually fill up and are split the same way that a data page is split.
Example Code Showing Page Splits
CREATE DATABASE [PageSplitTest];
GO
USE [PageSplitTest];
GO
CREATE TABLE [dbo].[TestTable]
(
[id] [int] IDENTITY(1,1) NOT NULL,
[FirstName] [NVARCHAR](3500) NOT NULL,
CONSTRAINT [PK_Customers] PRIMARY KEY CLUSTERED ([id] ASC)
);
DBCC IND(PageSplitTest, 'TestTable', 1);
INSERT INTO [dbo].[TestTable] ([FirstName])
VALUES (REPLICATE('X', 3500));
GO
--
DBCC IND(PageSplitTest, 'TestTable', 1);

You can see at this point the clustered index (id of 1) as reported from DBCC IND shows two pages in the index, page type 10 is the IAM (Index Allocation Map) page and a page of type 1 which contains the rows in the table.
SELECT *
FROM [dbo].[TestTable];
SELECT sys.fn_PhysLocFormatter(t.%%physloc%%),
*
FROM [dbo].[TestTable] as t;

In the second query, the first column is the output from fn_PhysLocFormatter which shows the physical location of the row. The first number (1) is the data file number, the second number (306) is the page and the 0 is the row number in that page.
Lets add another row and see how it looks.
-- insert a second row
INSERT INTO [dbo].[TestTable] ([FirstName])
VALUES (REPLICATE('Y', 3500));
SELECT sys.fn_PhysLocFormatter(t.%%physloc%%),
*
FROM [dbo].[TestTable] as t;

With two rows inserted, with 3500 NVarChar characters (2 bytes each char) you can see that only one rows fits per page, and the pages allocated are 306 and 309. If we take a look at DBCC IND we can see that the clustered index (the only index) has a total of 4 pages.
DBCC IND(PageSplitTest, 'TestTable', 1);

The four pages are the original IAM page (type 10), two pages for data (type 1) pages 306 and 309 as we saw above, and another page of type 2 which is the index page, the actual btree with the index structure.
Now we add a smaller row, only 25 nvarchar characters, which should fit into an existing page, lets see what happens.
INSERT INTO [dbo].[TestTable] ([FirstName])
VALUES (REPLICATE('a', 25));
SELECT sys.fn_PhysLocFormatter(t.%%physloc%%),
*
FROM [dbo].[TestTable] as t;
DBCC IND(PageSplitTest, 'TestTable', 1);
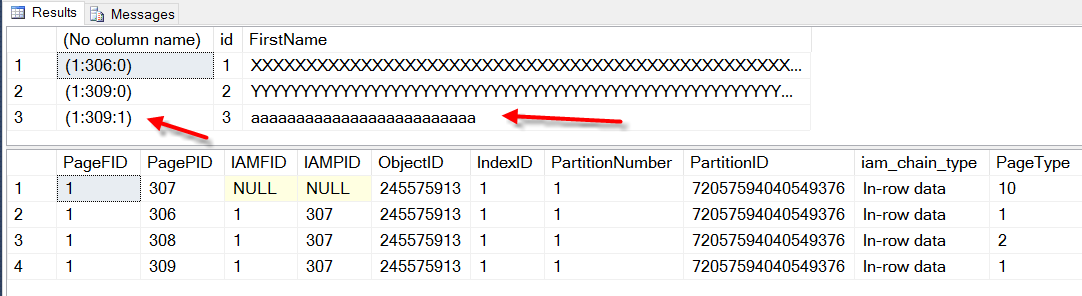
Here we see that the new row was inserted into page 309, no new pages were allocated and DBCC IND shows the same 4 pages as before.
So lets insert a few more rows, and see where they end up. These are also smaller rows with a length of 25 nvarchar characters.
INSERT INTO [dbo].[TestTable] ([FirstName])
VALUES (REPLICATE('b', 25));
INSERT INTO [dbo].[TestTable] ([FirstName])
VALUES (REPLICATE('c', 25));
INSERT INTO [dbo].[TestTable] ([FirstName])
VALUES (REPLICATE('d', 25));
INSERT INTO [dbo].[TestTable] ([FirstName])
VALUES (REPLICATE('e', 25));
SELECT sys.fn_PhysLocFormatter(t.%%physloc%%),
*
FROM [dbo].[TestTable] as t;
DBCC IND(PageSplitTest, 'TestTable', 1);
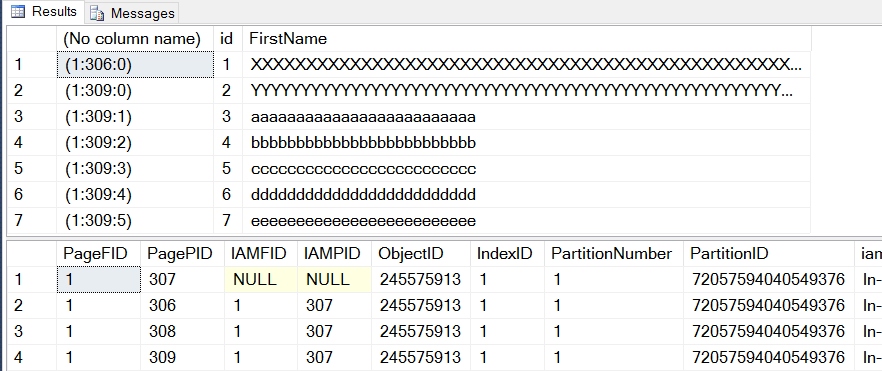 All of the newly inserted rows fit into page 309, and there are no new pages allocated. So what happens if you update one of those rows, lets update row 5 to a size that won’t fit in the current page and see what happens.
All of the newly inserted rows fit into page 309, and there are no new pages allocated. So what happens if you update one of those rows, lets update row 5 to a size that won’t fit in the current page and see what happens.
UPDATE [dbo].[TestTable]
SET [FirstName] = REPLICATE('c', 3500)
WHERE id = 5;
SELECT sys.fn_PhysLocFormatter(t.%%physloc%%),
*
FROM [dbo].[TestTable] as t;
DBCC IND(PageSplitTest, 'TestTable', 1);
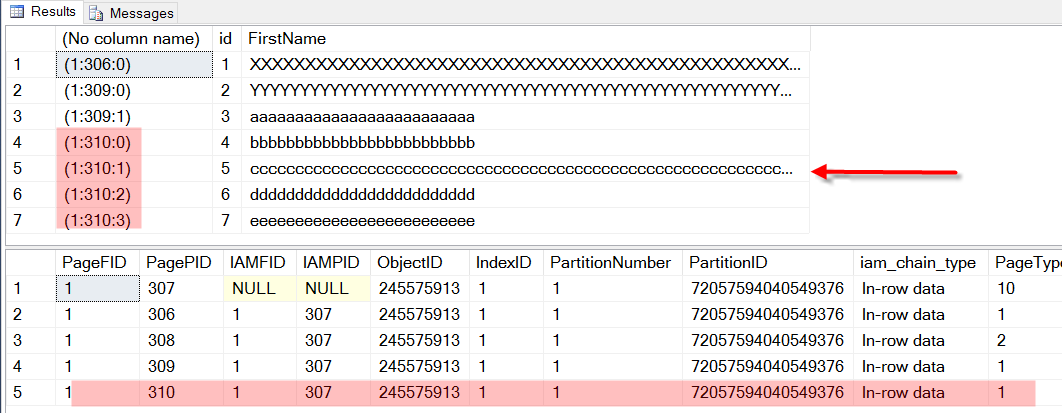
You can see here that several of the rows were moved from page 309 into 310 the newly allocate page. The act of moving these from one page to another to make room for the insert or update is known as a page split. The clustered index now has 5 pages instead of 4.
So what happens if we update row 5 again and shrink the size of the data back to the original?
UPDATE [dbo].[TestTable]
SET [FirstName] = REPLICATE('c', 25)
WHERE id = 5;
SELECT sys.fn_PhysLocFormatter(t.%%physloc%%),
*
FROM [dbo].[TestTable] as t;
DBCC IND(PageSplitTest, 'TestTable', 1);
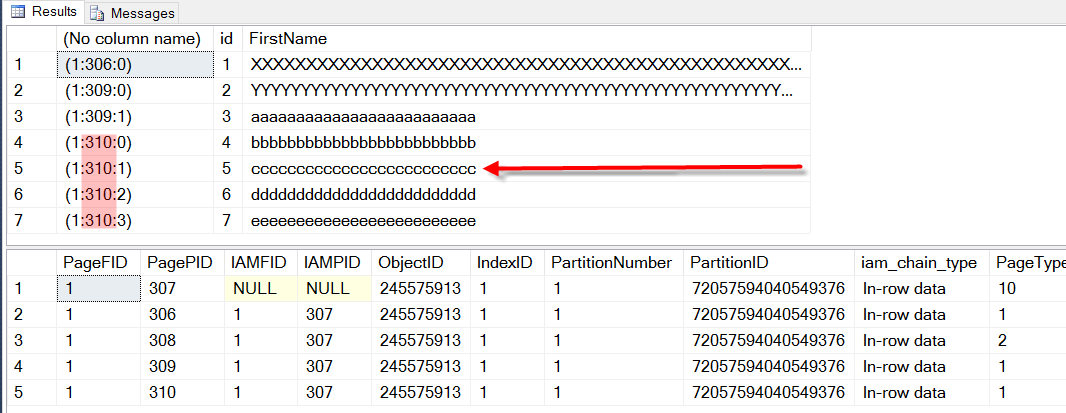 After the update, you can see that nothing has change, all rows are in the same page that they were in before the update, the table (clustered index) is just a bit more fragmented than before taking up 5 pages when it could take up 4.
After the update, you can see that nothing has change, all rows are in the same page that they were in before the update, the table (clustered index) is just a bit more fragmented than before taking up 5 pages when it could take up 4.
Tracking Page Splits
There are many ways to track page splits, you can use the performance monitor, Extended Events, dm_os_performance_counters, the transaction log, or other ways. Let’s take a look at page splits via the transaction log.
SELECT *
FROM
fn_dblog (NULL, NULL)
WHERE
[Operation] = N'LOP_DELETE_SPLIT';
UPDATE [dbo].[TestTable]
SET [FirstName] = REPLICATE('c', 3500)
WHERE id = 5;
UPDATE [dbo].[TestTable]
SET [FirstName] = REPLICATE('d', 3500)
WHERE id = 6;
SELECT sys.fn_PhysLocFormatter(t.%%physloc%%),
*
FROM [dbo].[TestTable] as t;
DBCC IND(PageSplitTest, 'TestTable', 1);
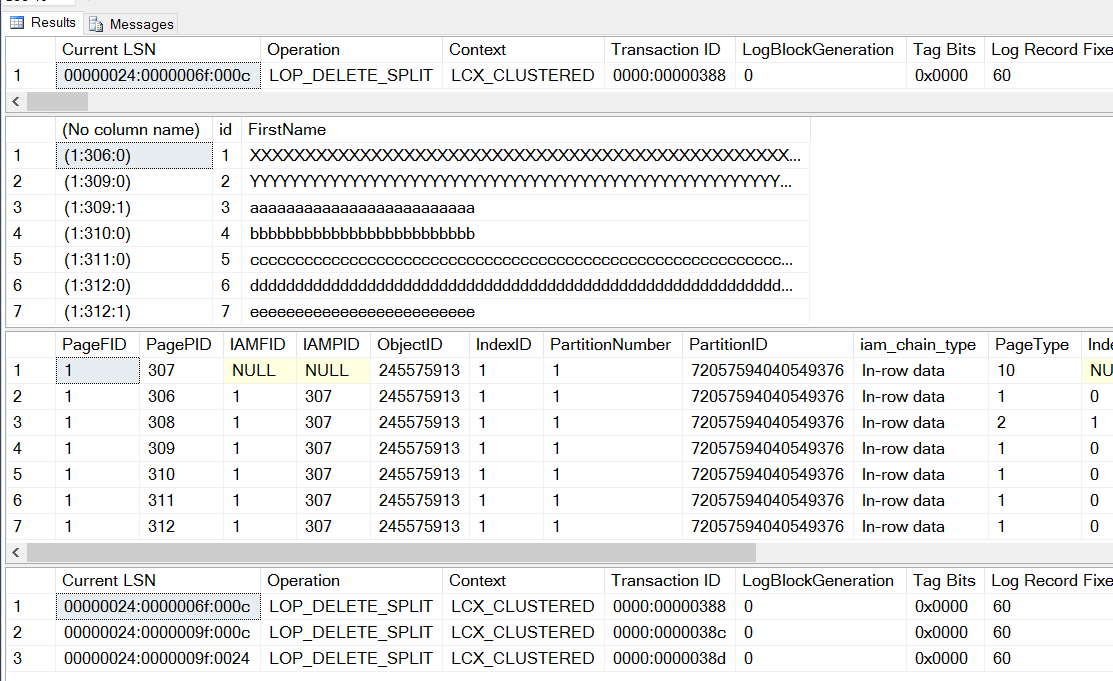
SELECT *
FROM fn_dblog (NULL, NULL)
WHERE [Operation] = N'LOP_DELETE_SPLIT';
Impact of SSDs versus Spinning Disks
If you are having I/O issues, page splits will likely be part of the I/O issue. SSDs are a great solution to improve the performance of your I/O, but not the only option. If you are I/O bound with lots of page splits, you may be able to reduce the I/O by finding the queries causing the most page splits and tuning those queries or tuning the table and index structure where the page splits are occurring. In a perfect scenario you could reduce the I/O caused by page splits and also get SSDs, but that’s not always a option.
Review
There is no single solution to resolving the impact of page splits. I hope that a better understanding of page splits will give you the knowledge to better assess your performance problems and at least understand why updates and inserts that cause page splits can impact your performance.
Need help? Let me know.
Related Links
More from Stedman Solutions:

Steve and the team at Stedman Solutions are here for all your SQL Server needs.
Contact us today for your free 30 minute consultation..
We are ready to help!
Hi Steve, Thanks for sharing your testing and analysis. Your work added to my understanding.
I think you have a math error in the first paragraph. If the rows are 100K each then even one row won’t fit on a page :). Perhaps you meant 100 bytes?
“If you have rows that are 100k each, you can fit about 80 of those rows into a given page”
Thanks
Ray
Ray, Thanks for catching the typo in the first paragraph. The typo has been fixed.
Have a great day!
-Steve Stedman
i am from Italy hello. Can you help me translate? /rardor
Sorry, but I don’t speak much Italian.
Questo è l’articolo più sorprendente.
-Steve Stedman