
Take the following sample code. Four similar tables with an INT IDENTITY, BIGINT IDENTITY, and two with UNIQUEIDENTIFIERS, one using newid() and the other with newsequentialid().
CREATE TABLE [dbo].[intIdentityTest]( [id] [int] IDENTITY(-2147483647,1) NOT NULL, [sometext] [varchar](200) NULL ) ON [PRIMARY]; GO CREATE TABLE [dbo].[bigIntIdentityTest]( [id] [bigint] IDENTITY(-9223372036854775808,1) NOT NULL, [sometext] [varchar](200) NULL ) ON [PRIMARY]; GO CREATE TABLE [dbo].[uniqueidentiferIdentityTest]( [id] [uniqueidentifier] NOT NULL default newid(), [sometext] [varchar](200) NULL ) ON [PRIMARY]; GO CREATE TABLE [dbo].[sequentialUniqueidentiferIdentityTest]( [id] [uniqueidentifier] NOT NULL default NEWSEQUENTIALID ( ), [sometext] [varchar](200) NULL ) ON [PRIMARY] GO INSERT INTO [dbo].[intIdentityTest] DEFAULT VALUES; INSERT INTO [dbo].[bigIntIdentityTest] DEFAULT VALUES; INSERT INTO [dbo].[uniqueidentiferIdentityTest] DEFAULT VALUES; INSERT INTO [dbo].[sequentialUniqueidentiferIdentityTest] DEFAULT VALUES; GO 100000 -- insert 100,000 rows
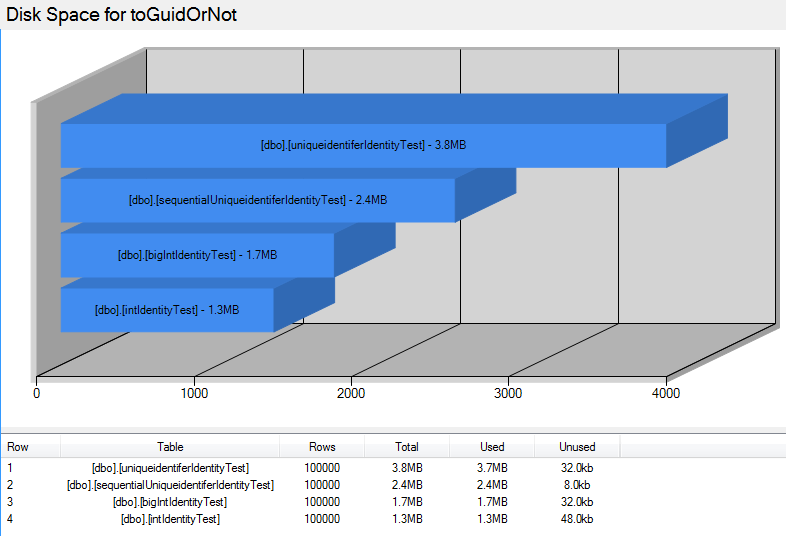
Once the tables are created and we insert 100,000 rows into each, they are very similar, but they take up very different amounts of disk space.
Using the Database Health Reports application, we can easily check in on the disk space used.

From this you can see that the total spaced used by either of the uniqueidentifiers is 31% larger than the BIGINT examples.
But looking back at the sample code you might argue that it isn’t a very realistic example because there is not primary key with a clustered index (common practice).
So lets try it again with a primary key with a clustered index on each of the tables.
CREATE TABLE [dbo].[intIdentityTest]( [id] [int] IDENTITY(-2147483647,1) NOT NULL, [sometext] [varchar](200) NULL, CONSTRAINT [PK_intIdentityTest] PRIMARY KEY CLUSTERED ( [id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY]; GO CREATE TABLE [dbo].[bigIntIdentityTest]( [id] [bigint] IDENTITY(-9223372036854775808,1) NOT NULL, [sometext] [varchar](200) NULL, CONSTRAINT [PK_bigIntIdentityTest] PRIMARY KEY CLUSTERED ( [id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY]; GO CREATE TABLE [dbo].[uniqueidentiferIdentityTest]( [id] [uniqueidentifier] NOT NULL default newid(), [sometext] [varchar](200) NULL, CONSTRAINT [PK_uniqueidentiferIdentityTest] PRIMARY KEY CLUSTERED ( [id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY]; GO CREATE TABLE [dbo].[sequentialUniqueidentiferIdentityTest]( [id] [uniqueidentifier] NOT NULL default NEWSEQUENTIALID ( ), [sometext] [varchar](200) NULL, CONSTRAINT [PK_sequentialUniqueidentiferIdentityTest] PRIMARY KEY CLUSTERED ( [id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO INSERT INTO [dbo].[intIdentityTest] DEFAULT VALUES; INSERT INTO [dbo].[bigIntIdentityTest] DEFAULT VALUES; INSERT INTO [dbo].[uniqueidentiferIdentityTest] DEFAULT VALUES; INSERT INTO [dbo].[sequentialUniqueidentiferIdentityTest] DEFAULT VALUES; GO 100000 -- insert 100,000 rows
Again, using the Database Health Reports application, I check in on the disk space used, which shows the following:
{kind=link}
Here you can see that the amount of space taken up by the uniqueidentifier compared to BIGINT is over twice the size. This additional size is mostly accounted for in the fragmentation caused by clustering on a uniqueidentifier.
Lets take a look at the index fragmentation, again using the Database Health Reports.

Here you can see that the uniqueidentifer test table is 99.4% fragmented. As you continue to add more to this table, it will continue to be defragmented.
Summary
Using uniqueidentifers as primary keys, and as clustered indexes can lead to trouble over time.
1. I suggest that if you can avoid it, you should avoid a uniqueidentifier for a primary key.
2. If you must use a uniqueidentifier, the use NEWSEQUENTIALID ( ) to generate the unique identifer, not NEWID().
More from Stedman Solutions:

Steve and the team at Stedman Solutions are here for all your SQL Server needs.
Contact us today for your free 30 minute consultation..
We are ready to help!
There’s a little drawback when using NEWSEQUENTIALID() because you can “guess” the next value.. Try this code:
use tempdb
go
drop table if exists test
go
create table test( id uniqueidentifier default (newsequentialid()), datum datetime not null default current_timestamp)
go
insert into test(datum) values(default)
go 100
select * from dbo.test
First, thank you for what you do! Major kudos to you and anyone else that takes the time to share their knowledge for free, especially with such thoughtfully coded examples that are meant to prove a point.
However, in this case, you’ve come to a seriously incorrect conclusion. And , PLEASE understand that is definitely NOT meant as a slam because nearly everyone on the entire planet that works with SQL Server and other relational database engines have come to the same conclusion using testing virtually identical to the test code you have in this article.as supposed “proof” of what they claim.
Here are some new points that few have ever even identified.
1. Random GUID are NOT a fragmentation problem. How we maintain them is! The supposed “Best Practices” of index maintenance that most of the whole bloody world has generally accepted is NOT a “Best Practice”, was never meant to be a “Best Practice”, and is actually a WORST PRACTICE because it does things like cause perpetual page splits and the resulting fragmentation in Random GUIDs and just about everything else where a Fill Factor could be used to prevent fragmentation
2. Totally contrary to what people think they know, Random GUIDs can actually be used to PREVENT fragmentation where IDENTITY and NEWSEQUENTIALID() cannot during commonly occurring INSERT/UPDATE patterns.
Now, I’m not one to “bring a knife to a gunfight”. :D I actually have demonstratable, repeatable, and accurate test code and results to back my claims up. Please see the following presentation to the end where I “DESTROY THE MYTH OF GUID FRAGMENTATION” and “LAY WASTE TO THE CURRENTLY ACCEPTED “BEST PRACTICE” INDEX MAINTENANCE”.
Seriously… watch it to the end. Just like the concept of replacing WHILE loops and other forms of RBAR (including rCTEs or “recursive CTEs) with Tally Tables, cCTEs (cascading CTEs, and other forms of “Pseudo-Cursors”, the presentation at the link below WILL change your professional life in the world of SQL Server and other relational databases. I guarantee it!
Here’s the link to the presentation I speak of. Watch it to the end and that’s NOT where the moderator says it is. There’s a hell of a surprise at the very end that makes it all even more worthwhile. :D
https://www.youtube.com/watch?v=qfQtY17bPQ4
Thanks Jeff. I appreciate the input.
Can I suggest that you revisit your article on the subject?