On Saturday morning, I announced the Database Corruption Challenge, and I had to abbreviate it as the DBCC, why not, acronym overloading isn’t always a bad thing.
There were 91 participants, 22 of which ended up with correct answers with no corruption and no data loss.
I created a database, with 3 bytes of corruption in one of the leaf node pages of a clustered index, however all I stated was that the database was corrupt, and it could be fixed with no data loss.
The number of different ways that people solved the problem was amazing. There were many attempts that did remove the corruption, and did recover all the rows, however many judged success as having the same number of rows as before, as a success. There were so many successful solutions that I think I will post one a day for the rest of the week, with the details explained. One solution even involved editing the database file on disk with a hex editor. I don’t have time to post all the good solutions right now.
The original corrupt database had been created on SQL Server 2014, but many people contacted me stating that they didn’t have SQL Server 2014 on their home computer, so I ended up creating a SQL Server 2008 version of the problem, but some were so driven to solve the challenge that they ended up installing SQL Server 2014 just to work the problem.

Nice work John. Thanks for playing along, I hope you enjoyed the experience. The next tweet from Mike Fal followed the post from John Morehouse.
I hope that John took this comment from Mike Fal as a great compliments, however it was soon corrected by AJ Mendo that it is more geek than nerd.
Either way, geeks or nerds, it was a good learning experience for those involved, and for me having to evaluate each solution to determine if it was indeed a valid solution with no data loss. Personally I ended up restoring the corrupt database and testing different solutions over 50 times this weekend.
The second person to submit a solution had this comment in their email.
Awesome Idea BTW, hope you disqualified Paul Randall right off the bat!
Now that wouldn’t be entirely fair. I was hoping that he would send in a solution to the challenge so that I would have a chance to learn from him.
Another comment for a participant who had a correct solution was:
Adding to my last email, and to be “complete”, I would then do the below to get the DB back to 100%. Then I’d implement regular DBCCs, better backup plans, and dig a shallow grave for the last DBA :-)
Very good point, other than the shallow grave part. If the corruption had been worse, or if there had not been the right non-clustered indexes, then we might have needed to go to an older backup, which didn’t exist in this scenario.
Some attempted to just drop the clustered index and rebuild it, that succeeded in removing the corruption, and it also succeeded in being able to access a the rows, however many people missed recovering the notes field for row #31.
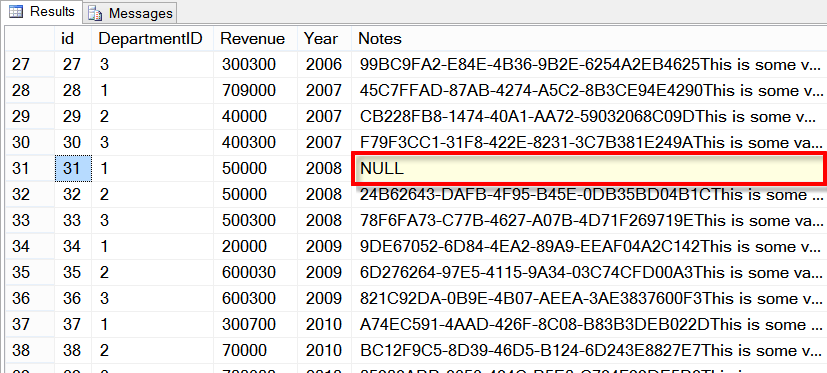
By dropping the clustered index and recreating it, all the data was correct except for this one column on row 31, the Notes column.
So how do we get the notes column back in this specific case, lets take a look at he winning solution. There are some other ways to get it that I will explore tomorrow.
The Winner: Brent Ozar
Six hours and 7 minutes after the challenge was posted the first correct answer came in from Brent Ozar.
Here is his solution. I have added the screenshots to help show the solution. Note… some of the formatting has been slightly adjusted to fit on the blogging format.
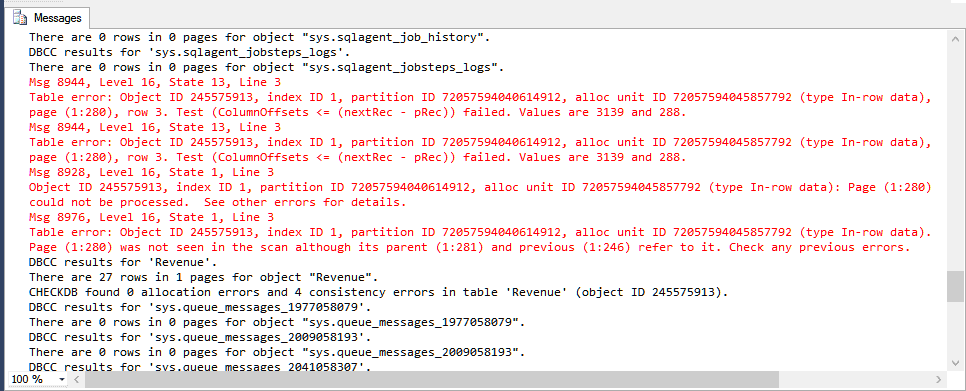
USE CorruptionChallenge1; GO /* Let's see what we're dealing with: */ DBCC CHECKDB(); /* Output that matters: Msg 8944, Level 16, State 13, Line 1 Table error: Object ID 245575913, index ID 1, partition ID 72057594040614912, alloc unit ID 72057594045857792 (type In-row data), page (1:280), row 3. Test (ColumnOffsets <= (nextRec - pRec)) failed. Values are 3139 and 288. Msg 8944, Level 16, State 13, Line 1 Table error: Object ID 245575913, index ID 1, partition ID 72057594040614912, alloc unit ID 72057594045857792 (type In-row data), page (1:280), row 3. Test (ColumnOffsets <= (nextRec - pRec)) failed. Values are 3139 and 288. Msg 8928, Level 16, State 1, Line 1 Object ID 245575913, index ID 1, partition ID 72057594040614912, alloc unit ID 72057594045857792 (type In-row data): Page (1:280) could not be processed. See other errors for details. Msg 8976, Level 16, State 1, Line 1 Table error: Object ID 245575913, index ID 1, partition ID 72057594040614912, alloc unit ID 72057594045857792 (type In-row data). Page (1:280) was not seen in the scan although its parent (1:281) and previous (1:246) refer to it. Check any previous errors. Oof. Index ID 1 = clustered index. Alright, let's see what this table is: */
SELECT * FROM sys.objects WHERE object_id = 245575913;

SELECT * FROM dbo.Revenue;
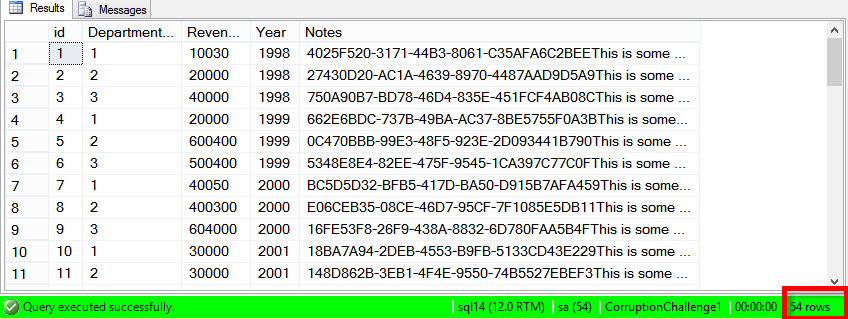
/* Pretty simple, 54 rows. Does it have any indexes? */ EXEC dbo.sp_BlitzIndex @DatabaseName='CorruptionChallenge1', @SchemaName='dbo', @TableName='Revenue';
If you don’t have sp_BlitzIndex you can download it from Brent Ozar. I would recommend having it and the other tools First Responder Kit available.
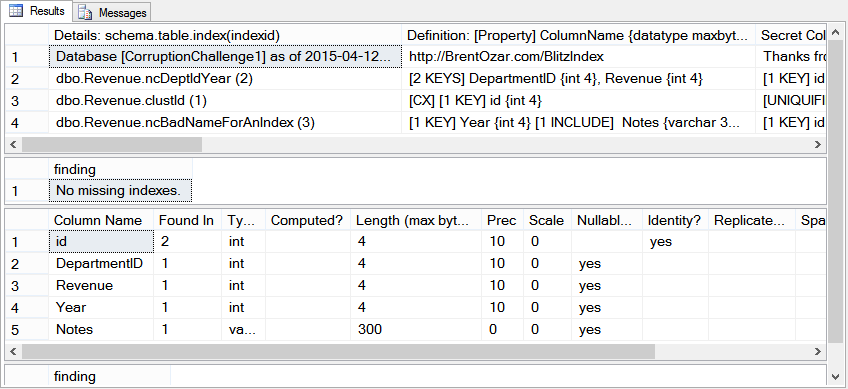
/* Which yields these index definitions: CREATE INDEX [ncDeptIdYear] ON [dbo].[RevenueBackup] ( [DepartmentID], [Revenue] ) WITH (FILLFACTOR=100, ONLINE=OFF, SORT_IN_TEMPDB=OFF); CREATE CLUSTERED INDEX [clustId] ON [dbo].[RevenueBackup] ( [id] ) WITH (FILLFACTOR=100, ONLINE=OFF, SORT_IN_TEMPDB=OFF); CREATE INDEX [ncBadNameForAnIndex] ON [dbo].[RevenueBackup] ( [Year] ) INCLUDE ( [Notes]) WITH (FILLFACTOR=100, ONLINE=OFF, SORT_IN_TEMPDB=OFF); Let's check the contents of each index against the clustered index: */ SELECT SUM(DepartmentID), SUM(Revenue) FROM dbo.Revenue WITH (INDEX=clustId); SELECT SUM(DepartmentID), SUM(Revenue) FROM dbo.Revenue WITH (INDEX=[ncDeptIdYear]);
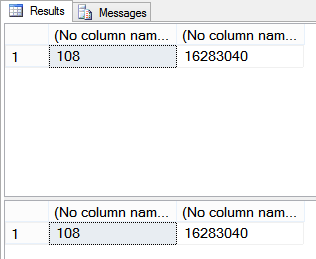
/* That one looks good. I know, I'm really cheating here - there could be differences between rows or null values that could screw me, but I'm trying to win a contest with 30 minutes of time before dinner. People are probably gonna end up reading this and going, "Wow, Brent sucks at recovering from corruption," but if you're planning to call me to fix your corrupt databases when I'm en route to dinner, you're going to be in for a fun surprise. Let's try the next one: */ SELECT SUM(Year), SUM(LEN(Notes)) FROM dbo.Revenue WITH (INDEX=clustId); SELECT SUM(Year), SUM(LEN(Notes)) FROM dbo.Revenue WITH (INDEX=[ncBadNameForAnIndex]);
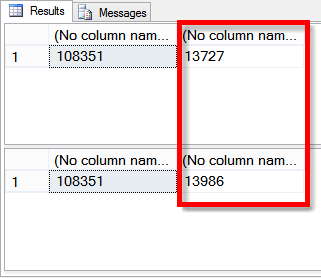
/* DIABOLICAL. There's more data for Notes in the nonclustered
index. Let's see what's different: */
SELECT rNC.*, r.*
FROM dbo.Revenue rNC WITH (INDEX=[ncBadNameForAnIndex])
LEFT OUTER JOIN dbo.Revenue r WITH (INDEX=clustId) ON r.id = rNC.id
WHERE rNC.Notes <> r.Notes OR r.Notes IS NULL;

/* For record id 31, the non-clustered index has a Notes
value, but the clustered index does not.
OK, let's first create a backup table with the same stuff
as the clustered index: */
CREATE TABLE [dbo].[RevenueBackup](
[id] [int] IDENTITY(1,1) NOT NULL,
[DepartmentID] [int] NULL,
[Revenue] [int] NULL,
[Year] [int] NULL,
[Notes] [varchar](300) NULL
) ON [PRIMARY]
GO
SET IDENTITY_INSERT dbo.RevenueBackup ON;
INSERT INTO dbo.RevenueBackup(id, DepartmentID, Revenue, Year, Notes)
SELECT * FROM dbo.Revenue;
SET IDENTITY_INSERT dbo.RevenueBackup OFF;
/* Then let's fix the data for record 31: */
UPDATE dbo.RevenueBackup
SET Notes = (SELECT Notes FROM dbo.Revenue WITH
(INDEX=[ncBadNameForAnIndex]) WHERE id = 31)
WHERE id = 31;
/* Make sure we got data, because I'm paranoid: */
SELECT * FROM dbo.RevenueBackup WHERE id = 31;

/* At this point, we've done DBCC CHECKDB(HUMAN VERSION). Let's have SQL Server
do its thing and see if it can fix things up without my help: */
ALTER DATABASE CorruptionChallenge1
SET SINGLE_USER
WITH ROLLBACK IMMEDIATE;
GO
DBCC CHECKDB ('',REPAIR_REBUILD);
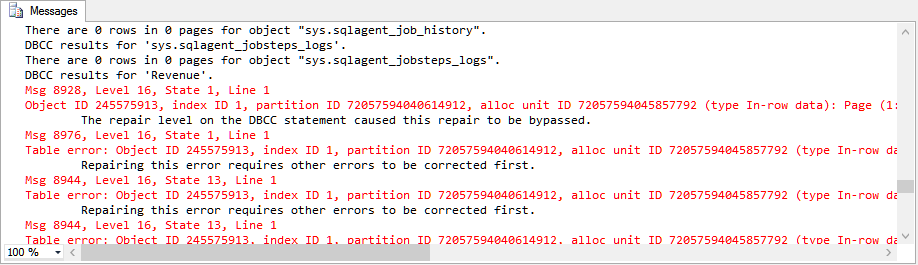
/*
Output is a sad, sad trombone:
DBCC results for 'Revenue'.
Msg 8928, Level 16, State 1, Line 91
Object ID 245575913, index ID 1, partition ID 72057594040614912, alloc unit ID 72057594045857792 (type In-row data): Page (1:280) could not be processed. See other errors for details.
The repair level on the DBCC statement caused this repair to be bypassed.
Msg 8976, Level 16, State 1, Line 91
Table error: Object ID 245575913, index ID 1, partition ID 72057594040614912, alloc unit ID 72057594045857792 (type In-row data). Page (1:280) was not seen in the scan although its parent (1:281) and previous (1:246) refer to it. Check any previous errors.
Repairing this error requires other errors to be corrected first.
Msg 8944, Level 16, State 13, Line 91
Table error: Object ID 245575913, index ID 1, partition ID 72057594040614912, alloc unit ID 72057594045857792 (type In-row data), page (1:280), row 3. Test (ColumnOffsets <= (nextRec - pRec)) failed. Values are 3139 and 288.
Repairing this error requires other errors to be corrected first.
Msg 8944, Level 16, State 13, Line 91
Table error: Object ID 245575913, index ID 1, partition ID 72057594040614912, alloc unit ID 72057594045857792 (type In-row data), page (1:280), row 3. Test (ColumnOffsets <= (nextRec - pRec)) failed. Values are 3139 and 288.
Repairing this error requires other errors to be corrected first.
There are 27 rows in 1 pages for object "Revenue".
Alright, let's do the nasty:
*/
DBCC CHECKDB ('',REPAIR_ALLOW_DATA_LOSS);
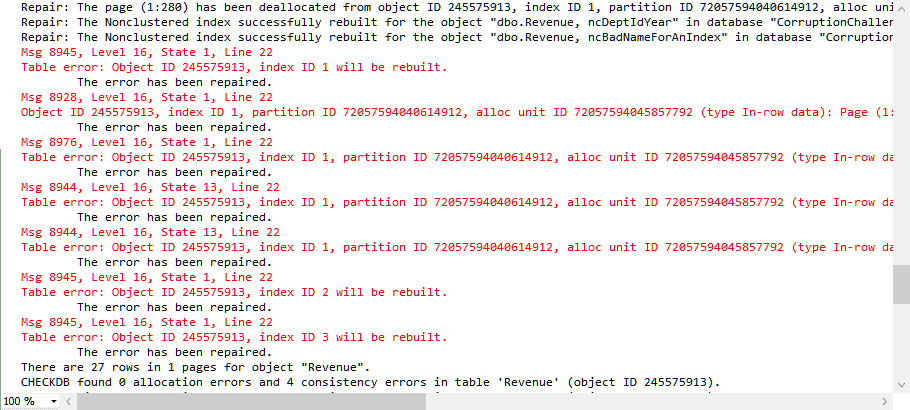
/* And run it again just to be safe: */ DBCC CHECKDB();
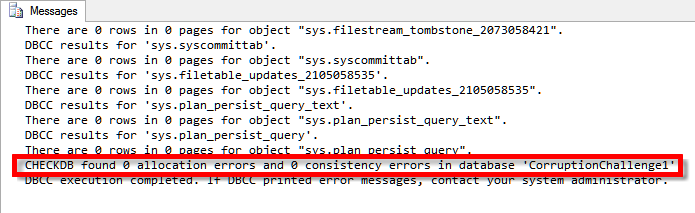
/* Whew. Comes back clean. Now how's the data look? */ SELECT * FROM dbo.Revenue;
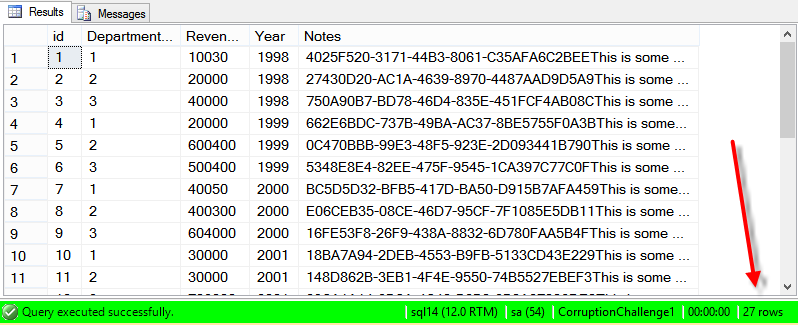
/* HA, only 27 rows. Sorry, SQL Server, you are the weakest link. If this was a larger table, I'd just rename the backup table, but here I'm going to put the data back in just to avoid dealing with security issues, triggers, etc. Note that I'm taking a lot of shortcuts since this was the only table in the database, with no referential integrity or anything. */ TRUNCATE TABLE dbo.Revenue; SET IDENTITY_INSERT dbo.Revenue ON; INSERT INTO dbo.Revenue(id, DepartmentID, Revenue, Year, Notes) SELECT * FROM dbo.RevenueBackup; SET IDENTITY_INSERT dbo.Revenue OFF; SELECT * FROM dbo.Revenue;
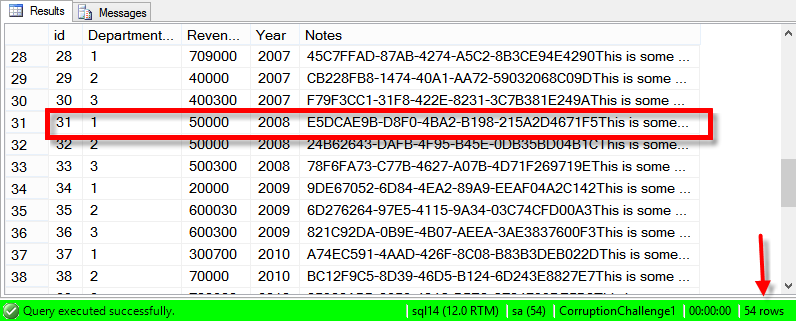
/* Got our 54 rows back, and row 31 has valid notes. Let people back into the club: */ ALTER DATABASE CorruptionChallenge1 SET MULTI_USER; GO
That’s how Brent Ozar won this weeks Database Corruption Challenge. My favorite part of his whole solution was this comment “but I’m trying to win a contest with 30 minutes of time before dinner.”
One thing that I liked in his solution to determine what columns were possibly corrupt was to compare the data for a column in the clustered index, to the data for that column in the non-clustered index.
<pre>SELECT SUM(Year), SUM(LEN(Notes)) FROM dbo.Revenue WITH (INDEX=clustId); SELECT SUM(Year), SUM(LEN(Notes)) FROM dbo.Revenue WITH (INDEX=[ncBadNameForAnIndex]);
This was a quick and dirty way to find out that something was not right with the Notes column, but to also confirm that things appeared to be fine in the other columns. In a real scenario, I might do a more exhaustive compare once things look mostly right, but this solution was a quick and easy way to find that something was missing in the Notes column.
Other Winners
First, I would like to say that I consider everyone who participated as a winner. I don’t mean that like everyone in little league gets a trophy, even if they were horrible ball players. What I mean here is that everyone who participated took time away from their busy personal time on the weekend to practice something that could at any point be vitally important to the future of their employment, and the future of their company.
Here is the list of runner up winners. All these participants provided a solution that fixed the corruption with no data loss.
- Patrick Keisler
- Rob Farley
- Parikshit Savjani
- Sébastien Piché
- Ivan Rodriguez Camejo
- Dave Walden
- John Morehouse
- Subhro Saha
- Robin Watkins
- Jon Gurgul
- André Kamman
- Damian Widera
- Rui Bastos
- Neil Abrahams
- Nicolette Carpenter Boddie
- wBob
- Walden H. Leverich
- Michel Bruggeman
- Shawn Johnson
- John Sterrett
- Bogdan Sahlean
- Dan Brennan
- Pedro Ferreira
Next Event
The next event will be coming soon. Here is a list of things I would do different:
- Provide a SQL Server 2008 version of the contest, for those who don’t have SQL Server 2014. A 2008 version would restore on SQL Server 2008, SQL Server 2008R2, SQL Server 2012 and SQL Server 2014.
- Provide a stored procedure to run that validates the solution so that the participants could get immediate feedback on their results.
- Make it a bit more difficult. This solution was a fun introduction, but it did lack some of the real world constraints that you run across when you have more than just one table in a database. Things like foreign key constraints.
- Announce the time for next weeks competition in advance. (hint… its going to be Friday April 17th at 5:00pm Pacific time)
I am open to any other suggestions.
There was one request to not post the competition on the weekend. Honestly the weekend is the only time that I have available to follow up with each individual participant when they send in their results.
If This Was a Real Emergency
What I found reading through the 90+ results is that many participants thought that they had the correct solution but did not. Sometimes having a second person to validate assumptions and to help with a solution is good. If you have more than one DBA in your business, rely on the other DBAs to help you out. Come up with a plan to figure out what may be corrupt before proceeding with any attempts to fix the problem. Also, be sure you have a secondary plan in case your first attempt goes wrong.
Shameless plug….. Stedman Solutions, LLC.
If you need help, and it is a real emergency you can contact me (Steve Stedman) any time (24/7). I offer consulting services to help in this scenario, and many other database and Disaster Recovery situations. Visit my company website http://StedmanSolutions.com for more details. For those who participated in the contest, you have my cell phone number in my email response. I have reasonable rates, and can help when you need it.
-Steve Stedman
More from Stedman Solutions:

Steve and the team at Stedman Solutions are here for all your SQL Server needs.
Contact us today for your free 30 minute consultation..
We are ready to help!
Ha!! I most certainly took Mike’s response as a compliment. Mike is a good friend and I wouldn’t take it any other way! ;-) Thanks for hosting this. Very cool challenge and I enjoyed it very much.
John – Look forward to the next challenge this coming Friday.
-steve
Fantastic idea for a challenge like this. I didn’t get the answer totally right (I got the corruption fixed but didn’t get row 31 back) but I certainly learned some more tricks that will help me in the future. Looking forward to the challenge this weekend!
Kris – I am glad to hear that you learned something new. That is the main point of the challenge. This weekends challenge will be an interesting on.
-Steve Stedman
This is a great learning tool for newbies like myself. I ended up moving the data then truncating the table and importing the data back. I see by the solutions that there was still a data integrity with my solution.
Keep them coming and is there a way to know about the challenges via email?
Thanks!!!
James, I have added you to my list to notify of the next challenge. There will be another one coming this Friday.
-Steve
YES!!!! Thank you!!!
I have a question and it’s confusing me.
Non-cluster index is based on cluster index key then how it get data from corrupted cluster index.
The non-clustered index has a copy of the fields specified in the index. These were originally copied from the clustered index prior to it being corrupt. Therefore you can sometimes use, as in this example the Non-clustered index to find the missing or corrupt data.
Novice here, and this is so helpful and exactly what I needed to start learning the nitty gritty things. Thanks Steve! and to the participants most especially to Brent Ozar for being so cool to join. -fan mode :)
Please it would be highly appreciated if you post other solutions too
Hi Manees, We have 10 weeks of corruption challenge solutions available for you.
https://stevestedman.com/server-health/database-corruption-challenge/
-Steve Stedman