SQL Server SEQUENCE

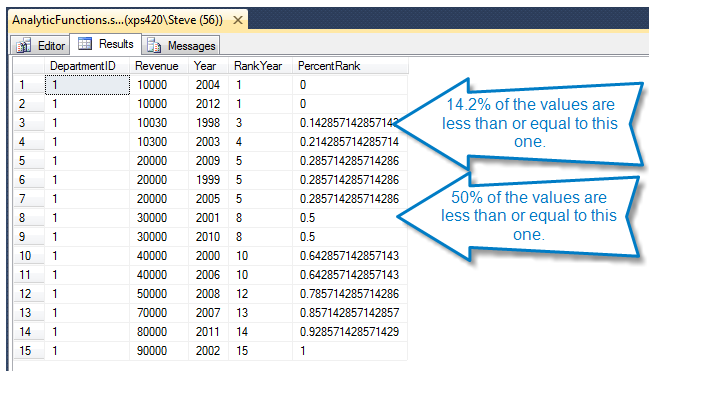
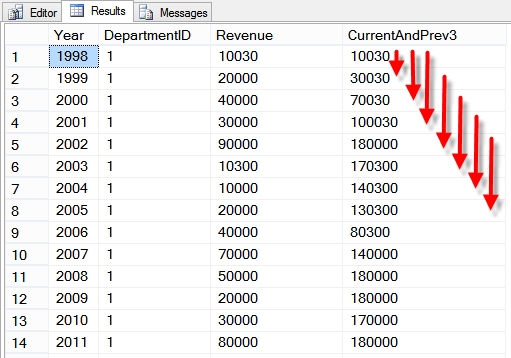
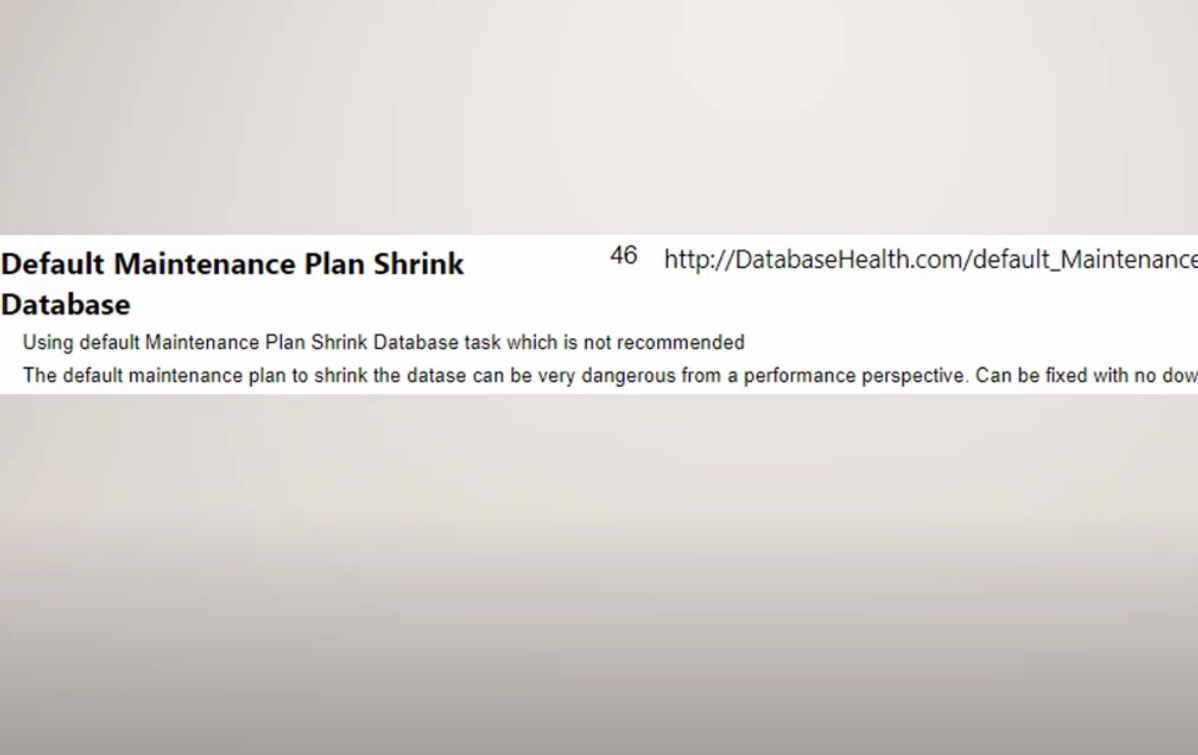
In 2012 SQL Server introduced the SEQUENCE object. Looking at the syntax it is very similar to how Oracle has implemented SEQUENCEs for many years. I believe that the SEQUENCE was introduced to aid in the transition of Oracle developers …