Using the OUTPUT Clause in TSQL for Auditing
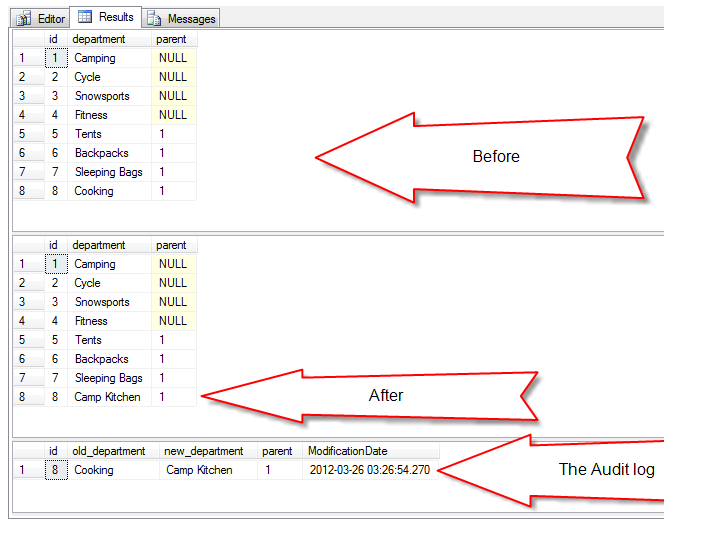
The OUTPUT clause is often times underappreciated by the TSQL programmer. There are many really interesting things that you can do with the OUTPUT clause, from inserting to two tables with one statement or to replace the SCOPE_IDENTITY option. For …