More TSQL Analytic Functions – PERCENT_RANK
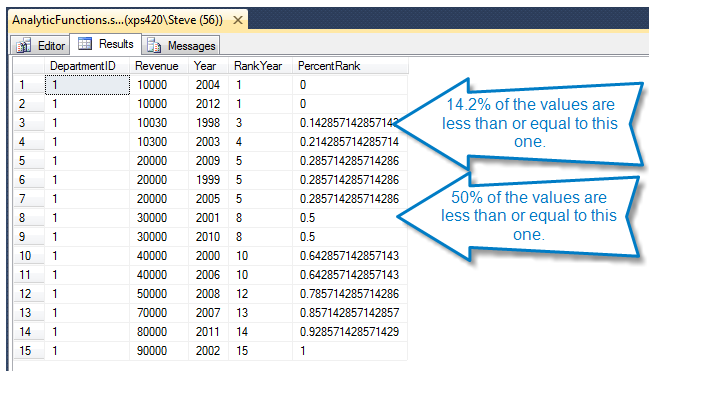
Percent rank is defined as the number of values that are the same or less than the current value divided by one less than the number of values. Percent rank is different than PERCENTILE, stay tuned for PERCENTILE_DISC and PERCENTILE_CONT …