SQL Server Tables – BTree or Linked List?

Is a clustered table in SQL Server a BTree or Linked List?
When you first learn about the structure behind clustered indexes in SQL Server, you find out that the clustered index is structured as a type of B+Tree where queries that make use of the tree structure to find the rows that you are looking for. However it is not the common belief that that table with the clustered index also happens to be a doubly linked list, and that the B+Tree can be completely skipped when running a query that uses the clustered index via a clustered index scan.
Take the following table and query as an example:
CREATE TABLE [dbo].[Orders]( [id] [int] IDENTITY(-2147483647,1) NOT NULL, [orderDate] [DATETIME] NOT NULL, [customerId] [int] NULL, [shippingType] varchar(100), [orderDetails] varchar(max), [totalPrice] DECIMAL(12, 2) CONSTRAINT [PK_Revenue] PRIMARY KEY CLUSTERED ([id] ASC, [orderDate]) );
Then insert a bunch of rows, and run a query.
SELECT * FROM [dbo].[Orders];
The way that SQL Server processes the query is with a clustered index scan, which touches every page in the table.
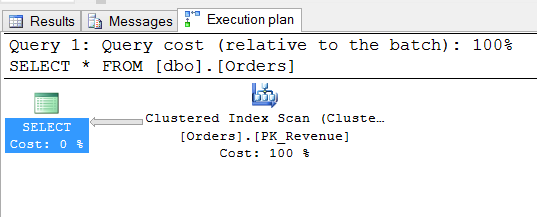
However since the plan calls for a scan, SQL Server can skip the B+Tree since every page contains a pointer to the next and previous page
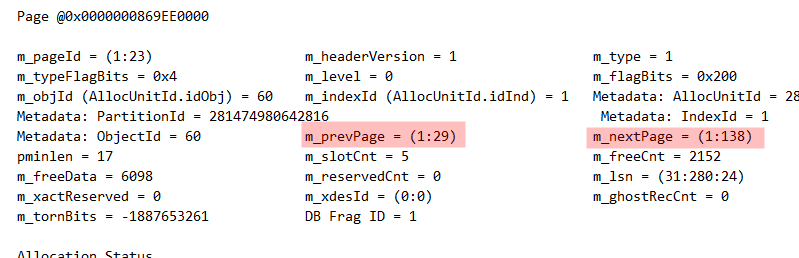
From this we can see that in addition to being a B+Tree, the layout of the table in a clustered index is also a doubly link list, where from any page you can find the next and previous page.
How do we know that the following query is using the m_nextPage pointer to the next page when the query is run.
SELECT * FROM [dbo].[Orders];
First off, we try running the query, and we include the undocumented fn_PhysLocFormatter and the %%physloc%% column to see what pages are being scanned.
SELECT sys.fn_PhysLocFormatter (%%physloc%%) AS [Location],
*
FROM [dbo].[Orders];
Which shows the following with the output from the fn_PhysLocFormatter shown with the page number highlighted. This indicates that after page 17 is scanned that the output starts pulling in data from page 20.
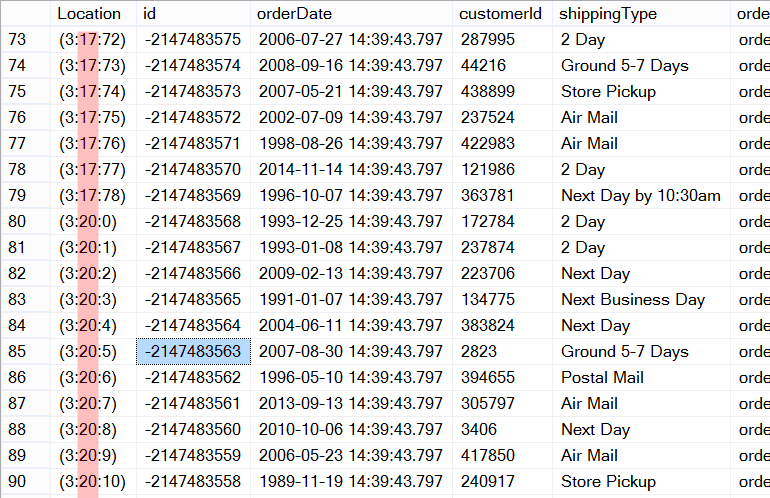
So how do we know that SQL Server is using the linked list to scan the query.
First when the query above was run it produced 73802 rows of output. Next we hack one of the m_nextPage pointers to point to a previous page in the list, rather then the correct location. This can be done with the undocumented DBCC WritePage, to modify the next pointer to point to a previous page.
WARNING: DBCC WritePage is a dangerous command, that should never be used on any production database. It may invalidate your ability to get support from Microsoft on issues that arise with that database going forward. It is not my intention to encourage anyone to use DBCC WritePage ever. This is just what I used to create a corrupt database, and since creating corrupt databases is not part of the role of most DBAs, you should not use DBCC WritePage. Consider yourself warned.
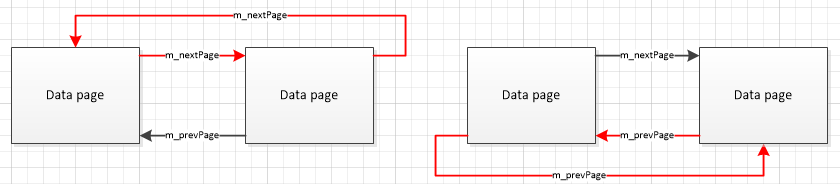
So instead of the normal linkage shown here:

You end up with an infinite loop like this:

Then we run the query again:
SELECT sys.fn_PhysLocFormatter (%%physloc%%) AS [Location],
*
FROM Customers;
Which rather than producing the original 73802 rows of output runs for 25 minutes and produces over 33 million rows of output before running my poor SQL Server VM out of disk space. Change the pointer back and the query runs just fine.
I tried modifying both the m_nextPage pointer and the m_prevPage pointer with many different pages in the table seeing similar results.
If you are simply selecting without and ORDER BY on your query then the m_nextPage pointer is uses. If you are querying with and ORDER BY on the clustering key DESC, then the m_prevPage pointer is used to walk through all the pages in the table.
In the above example where the m_nextPage pointer was causing an endless loop, you can get the rows back just fine with this query:
SELECT * FROM [dbo].[Orders] ORDER BY id DESC;
Which works just fine since it uses the m_prevPage pointer. But if you modify pointers in both directions, you are then unable to successfully query the data in either direction. Either way you end up with infinity loops which appear to have millions of rows until you dig into and find out that you have the same rows repeating.
So why would you do this? Two reasons that I can think of:
- To create a corrupt database as part of the Database Corruption Challenge.
- To prove that the m_nextPage and m_prevPage pointers are indeed being used in a clustered index scan as I have shown here. To answer the question of a BTree or Linked List.
Clustered Table as a BTree or Linked List
So to answer the question that I started of SQL Server Clustered Table as a B+Tree or a Linked List?
The answer is it is both. The B+Tree exists to be used for scanning, but when the query requires a clustered index scan the linked lists it used.
Related Links
More from Stedman Solutions:

Steve and the team at Stedman Solutions are here for all your SQL Server needs.
Contact us today for your free 30 minute consultation..
We are ready to help!
Leave a Reply