Corruption Challenge 1 – how I corrupted the database

Since the corruption challenge completed yesterday, I have had several request asking how I created the corrupt database. So here is the script that I used to create the Database Corruption Challenge 1.
First the initial setup. Most of this I stole from a query training session that I did several weeks ago. All I really needed was a table with some data in it.
CREATE DATABASE [CorruptionChallenge1]; GO USE [CorruptionChallenge1]; CREATE TABLE Revenue ( [id] INTEGER IDENTITY, [DepartmentID] INTEGER, [Revenue] INTEGER, [Year] INTEGER, [Notes] VARCHAR(300) ); INSERT INTO Revenue ([DepartmentID], [Revenue], [Year]) VALUES (1,10030,1998),(2,20000,1998),(3,40000,1998), (1,20000,1999),(2,600400,1999),(3,500400,1999), (1,40050,2000),(2,400300,2000),(3,604000,2000), (1,30000,2001),(2,30000,2001),(3,703000,2001), (1,90000,2002),(2,200200,2002),(3,80000,2002), (1,10300,2003),(2,1000,2003), (3,900300,2003), (1,10000,2004),(2,10000,2004),(3,100300,2004), (1,208000,2005),(2,200200,2005),(3,203000,2005), (1,40000,2006),(2,30000,2006),(3,300300,2006), (1,709000,2007),(2,40000,2007),(3,400300,2007), (1,50000,2008),(2,50000,2008),(3,500300,2008), (1,20000,2009),(2,600030,2009),(3,600300,2009), (1,300700,2010),(2,70000,2010),(3,700300,2010), (1,80000,2011),(2,80000,2011),(3,800200,2011), (1,100030,2012),(2,90000,2012),(3,900300,2012), (1,10000,2013),(2,90000,2013),(3,900100,2013), (1,100400,2014),(2,900300,2014),(3,903000,2014), (1,102000,2015),(2,902000,2015),(3,902000,2015); UPDATE Revenue SET [Notes] = CAST(NEWID() as VARCHAR(300)) + 'This is some varchar data just to fil out some pages... data pages are only 8k, therefore the more we fill up in each page, the more pages this table will flow into, thus simulating a larger table for the corruption example'; CREATE CLUSTERED INDEX [clustId] ON [dbo].[Revenue] ( [id] ASC ); CREATE NONCLUSTERED INDEX [ncDeptIdYear] ON [dbo].[Revenue] ( [DepartmentID] ASC, [Revenue] ASC ); CREATE NONCLUSTERED INDEX [ncBadNameForAnIndex] ON [dbo].[Revenue] ( [Year] ASC ) INCLUDE ( [Notes]) ; -- first lets look at the REVENUE table SELECT * FROM Revenue;
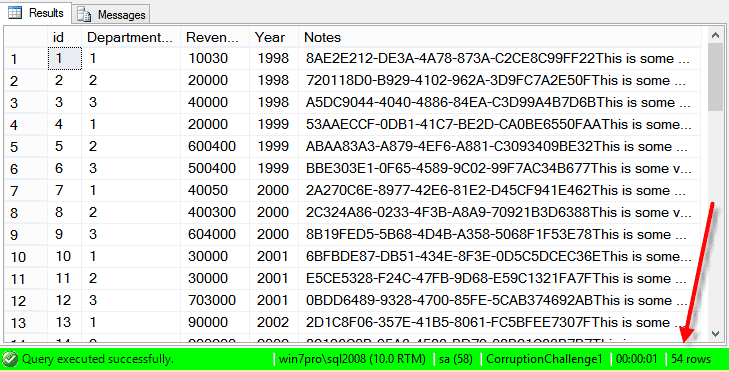
At this point the revenue table had 54 rows, and no corruption.
Next I used DBCC IND to look up the pages used by the clustered index of the table. My goal was to corrupt something in the clustered index.
DBCC IND(CorruptionChallenge1,'Revenue', 1) with no_infomsgs;

I choose one of the pages to corrupt. Lets use page #159, which is a leaf node in the clustered index, the page type of 1 indicates a data page, type 2 is the index structure, and 10 is the IAM. I could have used page 157 or 159 in this example. Your actual page numbers may vary.
-- turn on the DBCC output for commands like DBCC page DBCC TRACEON(3604) with no_infomsgs; -- the page comes from the earlier query DBCC Page(CorruptionChallenge1, 1, 159, 2) with no_infomsgs;
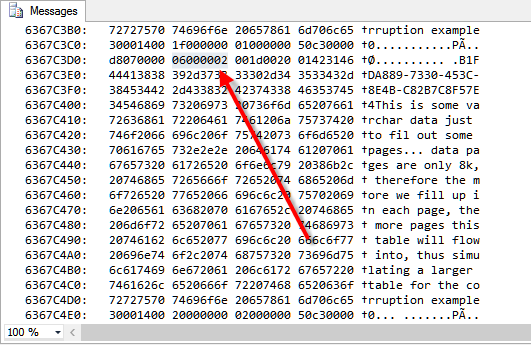
I scrolled through the output of DBCC Page until I found location 980, which in hex is 3D4, if you look for 3d4 in the last 3 digits of the address, which indicates the offset from the beginning of the page. Next I caused the corruption.
STOP HERE AND READ THIS WARNING.
DBCC WritePage is an extremely dangerous and undocumented DBCC Command. It takes an address in your SQL Server memory and lets you just overwrite it. DO NOT EVER USE THIS ON A PRODUCTION SYSTEM, EVER. Repeat that to yourself. DON NOT EVER USE IT ON A PRODUCTION SYSTEM.
So now that the warning is out of the way, I used DBCC WritePage to write to page 159, at location 980, 3 bytes of data. The data written was 0x616161 which converting the 61 ascii shows 3 lowercase letter a’s. Thats all, thats it, just 3 bytes, with the letter a.
DBCC WritePage(CorruptionChallenge1, 1, 159, 980, 3, 0x616161);

At this point you can see we have bad news, or good news if you were me trying to create a corrupt database. Next we run DBCC CheckDB to see what we have for corruption.
{kind=link}
DBCC CheckDB();
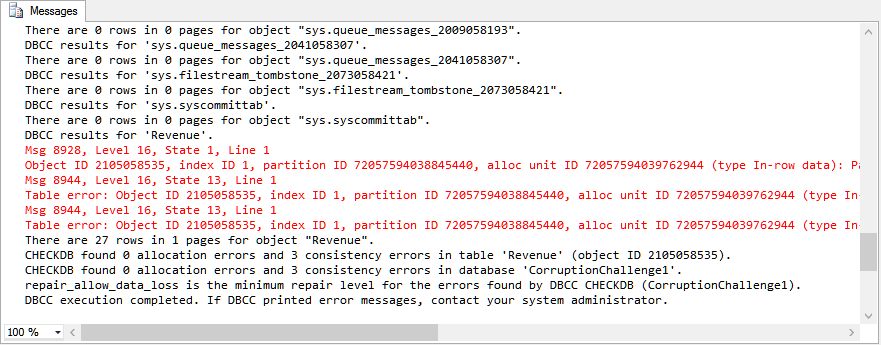
We now have a corrupt database with the corruption in the Revenue table. Running SELECT * FROM Revenue confirmed corruption in row 31, as shown in the example.
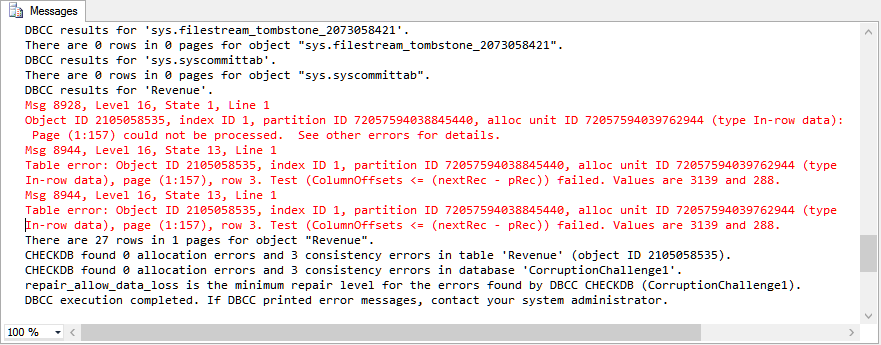{kind=link}
SELECT * FROM Revenue;
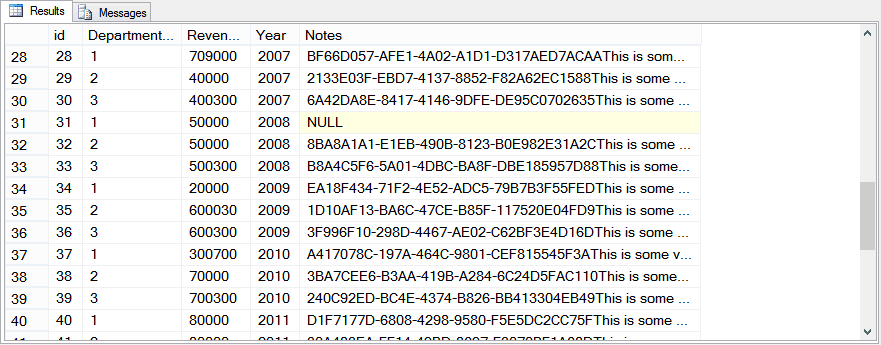
I then backed up the database to make it available for the Challenge.
Next I decided to attempt to fix it. I couldn’t exactly issue a Corruption Challenge without knowing how to fix it myself.
So I went about fixing it myself:
USE CorruptionChallenge1; GO -- lets see what we have SELECT * FROM Revenue; SELECT [id], [Year], [Notes] FROM Revenue WITH (INDEX (ncBadNameForAnIndex) ); SELECT [id], [DepartmentID], [Revenue] FROM Revenue WITH (INDEX (ncDeptIdYear) );
Which showed me that I was able to find the missing data in the non-clustered indexes.
CREATE TABLE [dbo].[Revenue2]( [id] [int] NOT NULL, [DepartmentID] [int] NULL, [Revenue] [int] NULL, [Year] [int] NULL, [Notes] [varchar](300) NULL ) ON [PRIMARY]; INSERT INTO Revenue2 SELECT r1.[id], r2.[DepartmentID], r2.[Revenue], r1.[Year], r1.[Notes] FROM Revenue r1 WITH (INDEX (ncBadNameForAnIndex) ) INNER JOIN Revenue as r2 WITH (INDEX (ncDeptIdYear) ) ON r1.[id] = r2.[id] ORDER BY r1.[id]; SELECT * FROM Revenue2;
The new table Revenue2 now had all the data that we needed, but Revenue was still corrupt.
-- first try to rebuild ALTER DATABASE [CorruptionChallenge1] SET SINGLE_USER WITH ROLLBACK IMMEDIATE; DBCC CheckTable(Revenue, REPAIR_REBUILD); ALTER DATABASE [CorruptionChallenge1] SET MULTI_USER WITH ROLLBACK IMMEDIATE; SELECT * FROM Revenue; -- no good, nothing changed -- the following causes parts of the table to be lost. ALTER DATABASE [CorruptionChallenge1] SET SINGLE_USER WITH ROLLBACK IMMEDIATE; DBCC CheckTable(Revenue, REPAIR_ALLOW_DATA_LOSS); ALTER DATABASE [CorruptionChallenge1] SET MULTI_USER WITH ROLLBACK IMMEDIATE; SELECT * FROM Revenue; DBCC CheckTable(Revenue); SELECT * FROM Revenue; DBCC CheckDB() with no_infomsgs;
At this point the corruption was gone, but there was a large amount of data missing from the Revenue table. We put the missing rows back in from the Revenue2 table.
SET IDENTITY_INSERT Revenue ON; INSERT INTO Revenue ([id], [DepartmentID], [Revenue], [Year], [Notes]) SELECT * FROM Revenue2 r2 WHERE r2.[id] NOT IN (SELECT [id] FROM Revenue); SET IDENTITY_INSERT Revenue OFF; SELECT * FROM Revenue; DBCC CheckDB() with no_infomsgs; DROP TABLE Revenue2;
That’s it, the corruption, and cleanup of the database. I then issued the first Corruption Challenge.
Whats next?
If you would like to be informed of the next Database Corruption Challenge, please subscribe to the mailing list.
More from Stedman Solutions:

Steve and the team at Stedman Solutions are here for all your SQL Server needs.
Contact us today for your free 30 minute consultation..
We are ready to help!
I’m curious, where did the 980 value come from? I’m assuming that you obtained that by randomly picking row 31 as the victim and located the row offset from the DBCC Page command (in the offset table). Is that correct?
John,
Wow – sorry for the slow response. 4.5 years later and I am finally getting around to a response.
Yes, Just picking row 31 and random and trying to overwrite somewhere in that row.
-Steve